
Image credit: Marta de la Figuera
This post is part of The Future of Coordinated Thinking: Series Index
Internet users speak with an Internet accent, but the only manner of speaking that doesn’t sound like an accent is one’s own.
What is the Internet? Why ask a question like this? As I mentioned in this piece’s equal companion Why We Should Be Free Online, we are in the Internet like fish in water and forget both its life-giving presence and its nature. We must answer this question, because, given a condition of ignorance in this domain, it is not a matter of whether but when one’s rights and pocket book will be infringed.
What sort of answer does one expect? Put it this way: ask an American what the USA is. There are at least three styles of answer:
- Someone who might never have considered the question before might say that this is their country, it’s where they live, etc.
- Another might say that America is a federal constitutional republic, bordering Canada to the North and Mexico to the South, etc.
- Another might talk about the country’s philosophy and its style of law and life, how, for example, the founding fathers wrote the Constitution so as to express rights in terms of what the government may not do rather than naming any entitlements, or how the USA does not have an official language.
The latter is the style of answer that I’m seeking, so as to elucidate the real human implications of what we have, the system’s style and the philosophy behind it. This will tell us, in the case of the Internet as it does in the case of the USA, why we have what we have, why we are astonishingly fortunate to have it in this configuration and what is wrong and how best to amend the system or build new systems to better uphold our rights and promote human flourishing.
In pursuit of this goal, I will address what I think are the three main mistaken identities of the Internet:
- The Web. The Web is the set of HTML documents, websites and the URLs connecting them; it is one of many applications which run on the Internet.
- Computer Network of Arbitrary Scale (CNAS). CNAS is a term of my own creation which will be explained in full later. In short: a Ford is a car, the Internet is a CNAS.
- Something Natural, Deistic or Technical. As with many other technologies, it is tempting to believe that the way the Internet is derives from natural laws or even technical considerations; these things are relevant, but the nature of the Iinternet is incredibly personal to its creators and users, and derives significantly from philosophy and other fields.
Finally, I will ask a supporting and related question, Who Owns the Internet? which will bring this essay to a close.
With our attention redirected away from these erroneous ideas and back to the actual Internet, we might then better celebrate what we have, and better understand what to build next. More broadly, I think that we are building a CNAS society and haven’t quite caught up to the fact; we need to understand the civics of CNAS in order to act and represent ourselves ethically. Otherwise, we are idiots: idiots in the ancient sense of the word, meaning those who do not participate.
Pulling on that strand, I claim, and will elaborate later, that we should be students of the Civics of CNASs, in that we are citizens of a connected society; and I don’t mean merely that our pre-existing societies are becoming connected, rather that the new connections afforded by tools like the Internet are facilitating brand new societies.
The Internet has already demonstrated the ability to facilitate communication between people, nationalities and other groups that would, in most other periods of time, have found it impossible not just to get along but to form the basis for communication through which to get along. With an active CNAS citizenry to steward our systems of communication, I expect that our achievements in creativity, innovation and compassion over the next few decades will be unimaginable.
- The Internet is Not the Web
- “Internet” Should Not Be Synonymous with “Computer Network of Arbitrary Scale”
- The Internet is not Natural, Deistic or even that Technical
- Who Owns and Runs the Internet?
- Conclusion: We Need a Civics of Computer Networks of Arbitrary Size, or We Are Idiots
The Internet is Not the Web
You may, dear reader, already be aware of this distinction; please do stick with me, though, as clarifying this misapprehension will clarify much else. The big difference between the Web and the Internet is this: the Internet is the global system of interconnected networks, running on the TCP/IP suite of protocols; the Web is one of the things you can do on the Internet, other things include email, file-sharing, etc.
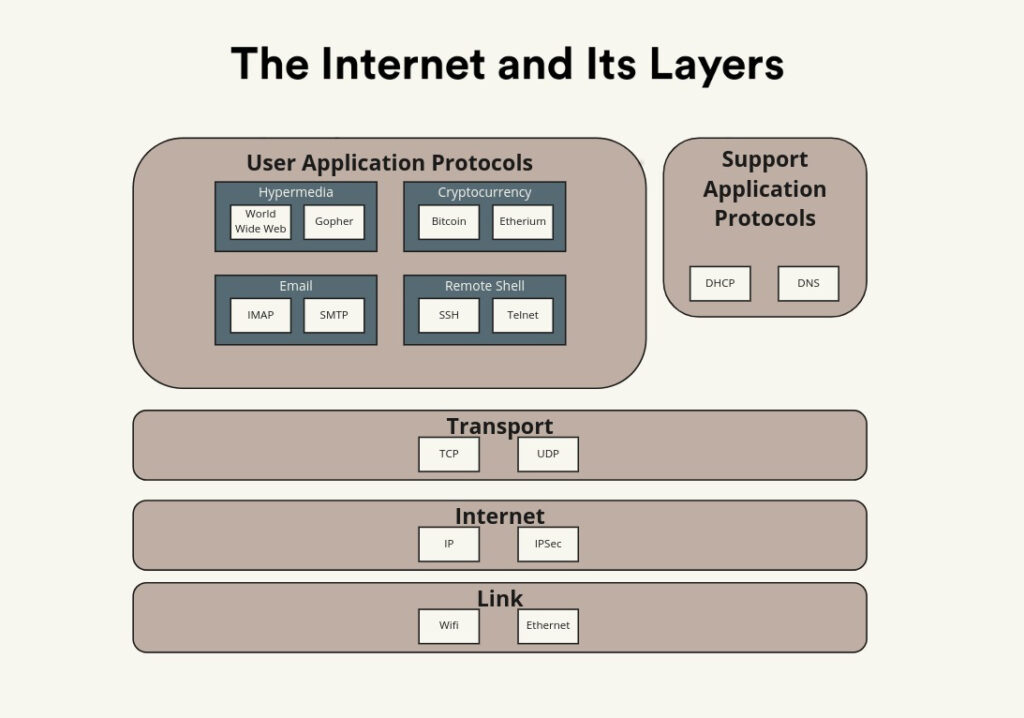
It’s not surprising that we confuse the two concepts, or say, go on the Internet when we mean go on the Web, in that the Web is perhaps the Internet application that most closely resembles the Internet itself: people and machines, connected and communicating. This is not unlike how, as a child, I thought that the monitor was the computer, disregarding the grey box. Please don’t take this as an insult; the monitor may not be where the processing happens, but it’s where the things that actually matter to us find a way to manifest in human consciousness.
As you can see in the above diagram, the Web is one of many types of application that one can use on the Internet. It’s not even the only hypermedia or hypertext system (the HT in HTTPS stands for hypertext).
The application layer sits on top of a number of other functions that, for the most part, one barely or never notices, and rightly so. However, we ought to concern ourselves with these things because of how unique and interesting they are, so let’s go through them one by one.
Broadly, the Internet suite is based on a system of layers. As I will explore later on, Internet literature actually warns against strict layering. Caveats aside, the Internet protocol stack looks like this:
Physical
Not always included in summaries of the Internet protocol suite, the physical layer refers to the actual physical connection between machines. This can be WiFi signals, CAT-5 cables, DSL broadband lines, cellular transmissions, etc.
Link
The link layer layer handles data transmission between devices. For example, the Link layer handles the transmission of data from your computer to your router, such as via WiFi or Ethernet, and then over, say, Ethernet via a DSL line to the target network (say to a webserver from which you’re accessing a site). The Link layer was specifically designed for it not to matter what the physical layer actually is, so long as it provides the basic necessities.
Internet
The Link layer handled the transmission between devices, and the Internet layer organizes the jumps between networks: in particular between Internet routers. The Link layer on its own can get the data from your computer to your router, but to get to the router for the target network, it needs the Internet layer’s help: this is why (confusingly) it’s called the Internet layer, it provides a means of interconnecting networks.
Your devices, your router, and all Internet-accessible machines are assigned the famous IP addresses, which come in the form of a 32-bit number, of four bytes separated by dots. My server’s IP address is 209.95.52.144.
This layer thinks in terms of getting data from one IP address to another.
Transport
Now, with the Link and Internet layers buzzing away, transmitting data, the Transport layer works above them both, establishing communication between hosts. This is akin to how I have something of a direct connection with someone to whom I send a letter, even though that letter passes through letterboxes and sorting offices; the Transport layer sets up this direct communication between machines, so that they can act independently with respect to the underlying conditions of the connection itself. There are a number of Transport layer protocols, but the most famous is TCP.
One of the most recognizable facets of the Transport layer is the port number. The TCP protocol assigns numbered “ports” to identify different processes; for the Web, for example, HTTP uses port 80 and HTTPS, port 443. To see this in action, try this tool, which will see which ports are open on a given host: https://pentest-tools.com/network-vulnerability-scanning/tcp-port-scanner-online-nmap — try it first with my server, omc.fyi.
This layer thinks in terms of passing data over a direct connection to another host.
Application
The Application layer is responsible for the practicalities associated with doing the things you want to do: HTTPS for the Web, SMTP for email, SSH for a remote command line connection, are all Application layer protocols. If it wasn’t clear by now, this is where The Web lives, it is one of many Applications running on the Internet.
How it Works in Practice
Here’s an example of how all this works:
- Assume a user has clicked on a Web link in their browser, and that the webserver has already received this signal, which manifests in the Application layer. In response, the server sends the desired webpage, using HTTPS, which lives on the Application layer.
- The Transport Layer is then responsible for establishing a connection (identified by a port) between the server and the user’s machine, through which to communicate.
- The Internet Layer is responsible for transmitting the appropriate data between routers, such as the user’s home router and the router at the location of the Web server.
- The Link Layer is responsible for transmitting data between the user’s machine and their router, between their router and the router for the webserver’s network, and between the webserver and its router.
- The Physical Layer is the physical medium that connects all of this: fiberoptic cable, phone lines, electromagnetic radiation in the air.
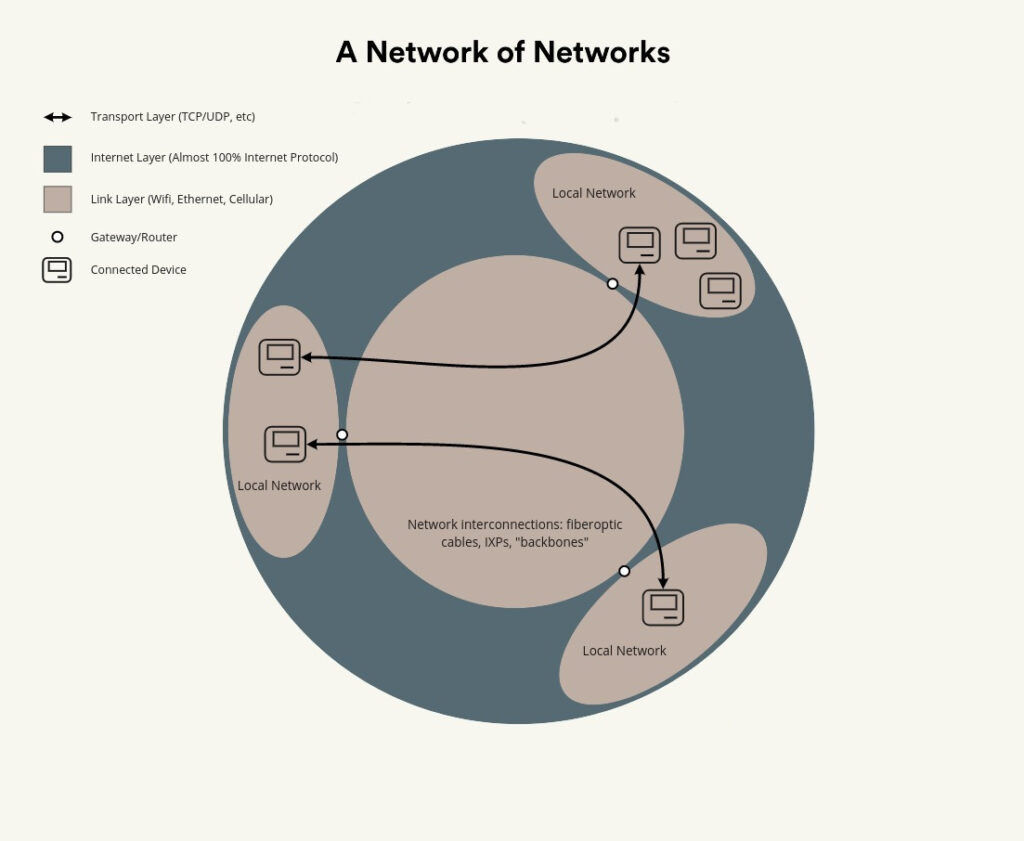
Why is this interesting? Well, firstly, I think it’s interesting for its importance; as I claim in this piece’s equal counterpart on Internet freedom, the Internet is used for so much that questions of communication are practically the same as questions of the Internet in many cases. Secondly, the Internet is Interesting for its peculiarity, which I will address next.
“Internet” Should Not Be Synonymous with “Computer Network of Arbitrary Scale”
When addressing the Internet as a system, there appear to be two ways in which people use the word:
- One refers to the Internet as in the system we have now and, in particular, that runs on the TCP/IP protocol suite.
- The other refers to the Internet as a system of interconnected machines and networks.
Put it this way: the first definition is akin to a proper noun, like Mac or Ford, the latter is a common noun, like computer or car.
This is not uncommon: for years I really thought that “hoover” was a generic term, and learned only a year or so ago that TASER is a brand name (the generic term is “electroshock weapon”). Then of course we have non-generic names that are, and some times deliberately so, generic-sounding: “personal computer” causes much confusion, in that it could refer to IBM’s line of computers by that name, something compatible with the former, or merely a computer for an individual to use; there is of course the Web, which is one of many hypertext systems that allow users to navigate interconnected media at their liberty, whose name sounds merely descriptive but, in fact, refers to a specific system of protocols and styles. The same is true for the Internet.
For the purpose of clarifying things, I’ve coined a new term: computer network of arbitrary scale (CNAS or seenas). A CNAS is:
- A computer network
- Using any protocol, technology or sets thereof
- That can operate at any scale
Point three is important: we form computer networks all the time, but one of the things about the Internet is that its protocols are robust enough for it to be global. If you activate the WiFi hotspot on our phone and have someone connect, that is a network, but it’s not a CNAS because, configured thus, it would have no chance of scaling. So, not all networks are CNASs; today, the only CNAS is the thing we call the Internet, but I think this will change in a matter of years.
There’s a little wiggle room in this definition: for example, the normal Internet protocol stack cannot work in deep space (hours of delay due to absurd distances, and connections that come in and out because the sun gets in the way make it hard), so one could argue the today’s Internet is not a CNAS because it can’t scale arbitrarily.
I’d rather keep this instability in the definition:
- Firstly, because (depending on upcoming discoveries in physics) it may be possible that no network can scale arbitrarily: there are parts of the universe that light from us will never reach, because of cosmic expansion.
- Secondly, because the overall system in which all this talk is relevant is dynamic (we update our protocols, the machines on the network change and the networks themselves change in size and configuration); a computer network that hits growing pains at a certain size, and then surmounts them with minor protocol updates didn’t cease to be a CNAS then become one again.
Quite interestingly, in this RFC on “bundle protocol” (BP) for interplanetary communication (RFCs being a series of publications by the Internet Society, setting out various standards and advice) the author says the following:
BP uses the “native” internet protocols for communications within a given internet. Note that “internet” in the preceding is used in a general sense and does not necessarily refer to TCP/IP.
This is to say that people are creating new things that have the properties of networking computers, and can scale, but are not necessarily based on TCP/IP. I say that we should not use the term Internet for this sort of thing; we ought to differentiate so as to show how undifferentiated things are (on Earth).
Similarly, much of what we call the internet of things isn’t really the Internet. For example, Bluetooth devices can form networks, sometimes very large ones, but it’s only really the Internet if they connect to the actual Internet using TCP/IP, which doesn’t always happen.
I hope, dear reader, that you share with me the sense that it is absolutely absurd, that our species has just one CNAS (the Internet) and one hypertext system with anything like global usage (the Web). We should make it our business to change this:
- One, to give people some choice
- Two, to establish some robustness (the Internet itself is robust, but relying on a single system to perform this function is extremely fragile)
- Three, to see if we can actually make something better
At this point I’m reminded of the scene in the punchy action movie Demolition Man, in which the muscular protagonist (frozen for years and awoken in a strange future civilization) is taken to dinner by the leading lady, who explains that in the future, all restaurants are Taco Bell.
This is and should be recognized to be absurd. To be clear, I’m not saying that the Internet is anything like Taco Bell, only that we ought to have options.
The Internet is not Natural, Deistic or even that Technical
I want to rid you of a dangerous misapprehension. It is a common one, but, all the same, I can’t be sure that you suffer from it; all I can say is that, if you’ve already been through this, try to enjoy rehearsing it with me one more time.
Here goes:
Many, if not most, decisions in technology have little to do with technical considerations, or some objective standard for how things should be; for the most part they relate, at best, to personal philosophy and taste, and, at worst, ignorance and laziness.
Ted Nelson provides a lovely introduction, here:
Here’s a ubiquitous example: files and folders on your computer. Let’s say I want to save a movie, 12 Angry Men, on my machine: do I put it in my Movies that Take Place Mainly in One Room folder with The Man from Earth, or my director Sidney Arthur Lumet folder with Dog Day Afternoon? Ideally I’d put it in both, but most modern operating systems will force me to put it in just one folder. In Windows (very bad) I can make it sort of show up in more than one place with “shortcuts” that break if I move the original, with MacOS (better) I have “aliases” which are more robust.
But why am I prevented from putting it in more than one place, ab initio? Technically, especially in Unix-influenced systems (like MacOS, Linux, BSD, etc.) there is no reason why not to: it’s just that the people who created the first versions of these systems decades ago didn’t think you needed to, or thought you shouldn’t—and it’s been this way for so long that few ask why.
A single, physical file certainly can’t be in more than one place at a time, but electronic constructs can; the whole point of electronic media is the ability to structure things arbitrarily, liberating us from the physical.
Technology is a function of constraints—those things that hold us back, like the speed of processors, how much data can pass through a communications line, money—and values: values influence the ideas, premises, conceptual structures that we use to design and build things, and these things often reflect the nature of their creators: they can be open, closed, free, forced, messy, neat, abstract, narrow.
As you might have guessed, the creators and administrators of technology often express choices (such as how a file can’t be in two places at once) as technicalities, sometimes this is a tactic to get one’s way, sometimes just ignorance.
Why does this matter? It matters because we won’t get technology that inculcates ethical action in us and that opens the scope of human imagination by accident, we need the right people with the right ideas to build it. In the case of the Internet, we were particularly fortunate. To illustrate this, I’m going to go through two archetypical values that shape what the Internet became, and explore how things could have been otherwise.
Robustness
See below a passage from RFC 1122. It’s on the long side, but I reproduce it in full for you to enjoy the style and vision:
At every layer of the protocols, there is a general rule whose application can lead to enormous benefits in robustness and interoperability [IP:1]:
“Be liberal in what you accept, and conservative in what you send”
Software should be written to deal with every conceivable error, no matter how unlikely; sooner or later a packet will come in with that particular combination of errors and attributes, and unless the software is prepared, chaos can ensue. In general, it is best to assume that the network is filled with malevolent entities that will send in packets designed to have the worst possible effect. This assumption will lead to suitable protective design, although the most serious problems in the Internet have been caused by unenvisaged mechanisms triggered by low-probability events; mere human malice would never have taken so devious a course!
Adaptability to change must be designed into all levels of Internet host software. As a simple example, consider a protocol specification that contains an enumeration of values for a particular header field — e.g., a type field, a port number, or an error code; this enumeration must be assumed to be incomplete. Thus, if a protocol specification defines four possible error codes, the software must not break when a fifth code shows up. An undefined code might be logged (see below), but it must not cause a failure.
The second part of the principle is almost as important: software on other hosts may contain deficiencies that make it unwise to exploit legal but obscure protocol features. It is unwise to stray far from the obvious and simple, lest untoward effects result elsewhere. A corollary of this is “watch out for misbehaving hosts”; host software should be prepared, not just to survive other misbehaving hosts, but also to cooperate to limit the amount of disruption such hosts can cause to the shared communication facility.
This is not just good technical writing, this is some of the best writing. In just a few lines, Postel assures us of the not a case of whether but when orientation that can almost be applied universally, which almost predicts Taleb’s Ludic Fallacy—how the things that really hurt you are those for which you weren’t being vigilant, especially not ones that belong to familiar, mathematical-feeling or game-like scenarios; Taleb identifies another error type: not planning enough for the scale of the damage—Postel understood that in a massively interconnected environment, small errors can compound into something disastrous.
Then Postel explains one of the subtler parts of of his imperative: on first reading, I had thought that Be liberal in what you accept meant “Permit communications that are not fully compliant with the standard, but which are nonetheless parseable”. It goes beyond this, meaning that one should do so while being liberal in an almost metaphorical sense: being tolerant of and therefore not breaking down in response to aberrant behavior.
This is stunningly imaginative: Postel set out how Internet hosts might communicate without imposing uniform of versions of the software among all Internet users. Remember, and as I mention this essay’s counterpart on freedom, the Internet is stunningly interoperable: today, in 2021, you still can’t reliably switch storage media formatted for Mac and Windows, but it’s so easy to hook new devices up to the Internet that people seem to say why not, giving us Internet toothbrushes and fridges.
Finally, the latter part, calling hosts to be Conservative in what you send, is likewise more subtle than one might gather on first reading. It doesn’t mean that one should merely adhere to the standards (which is hard enough), it means do so while avoiding doing something that, while permitted, risks causing issues in other devices that are out-of-date or not set up properly. Don’t just adhere to the standard, imagine whether some part of the standard might be obscure or new enough that using it might cause errors.
This supererogation reaches out of the bounds of mere specification and into philosophy.
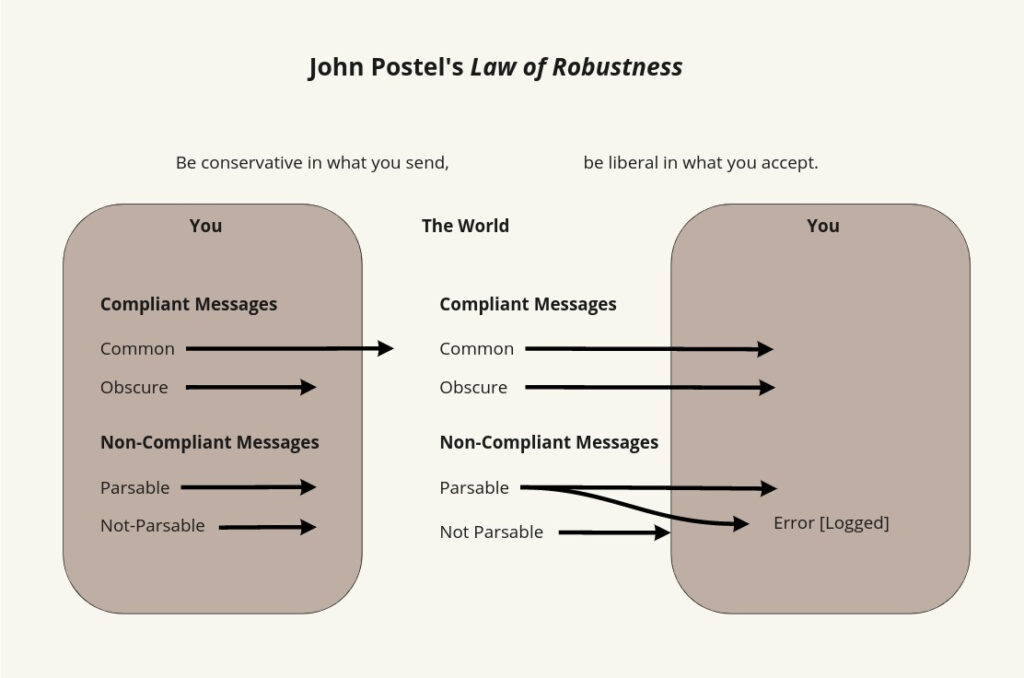
Postel’s Law is, of course, not dogma, and people in the Internet community have put forward proposals to move beyond it. I’m already beyond my skill and training, so can’t comment on the specifics here, but wish to show only that the Law is philosophical and beautiful, not necessarily perfect and immortal.
Simplicity
See RFC 3439:
“While adding any new feature may be considered a gain (and in fact frequently differentiates vendors of various types of equipment), but there is a danger. The danger is in increased system complexity.”
And RFC 1925:
“It is always possible to aglutenate multiple separate problems into a single complex interdependent solution. In most cases this is a bad idea.”
You might not need more proof than the spelling error to understand that the Internet was not created by Gods. But if you needed more, I wish for you to take note of how these directives relate to a particular style of creation, the implication being that the Internet could have gone many other ways and would have made our lives very different.
Meanwhile, these ideas are popular but actually quite against the grain, overall. With respect to the first point, it’s quite hard to find arguments to the contrary; this seems to be because features are the only way get machines to do things, and doing things is what machines is for—this seems to be the same as the reason why there’s no popular saying meaning “more is more” but we do have the saying “less is more,” because more is actually more, but things get weird with scale.
The best proponents for features and lots of them are certainly software vendors themselves, like Microsoft here:
Again, I’m not saying that features are bad—everything your computer does is a feature. This is, however, why it’s so tempting to increase them without limit.
Deliberately limiting features, or at least spreading features among multiple self-contained programs appears to have originated within the Unix community, best encapsulated by what is normally called the Unix philosophy, here are my two favorite points (out of four, from one of the main iterations of the philosophy):
- Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”.
- Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information.
The first point, there, neatly encompasses the two ideas referenced before in RFCs: don’t add too many features, don’t try to solve all your problems with one thing.
This philosophy is best expressed by the Internet Protocol layer of the stack (see the first section of this essay for our foolishly heathen recap of the layers). It is of course tempting to have IP handle more stuff; right now all it does is rout traffic between the end users, those users are responsible for anything more clever than that. This confers two main advantages:
- Simple systems mean less stuff to break; connectivity between networks is vital to the proper function of the Internet, better to lighten the load on the machinery of connection and have the devices on the edge of the network be responsible for what remains.
- Adding complex features to the IP layer, for example, would add new facilities that we could use; but any new feature imposes a cost on all users, whether it’s widely used or not. Again, better to keep things simple when it comes to making connections and transmitting data, and get complex on your own system and your own time.
At risk of oversimplifying, the way the Internet is is derived from a combination of technical considerations, ingenuity, and the combination of many philosophies of technology. There are, one can imagine, better ways in which we could have done this; but for now I want to focus on what could have been: imagine if the Internet had been built by IBM (it would have been released in the year 2005 and would require proprietary hardware and software) or Microsoft (it would have come out at around the same time, but would be run via a centralized system that crashes all the time).
Technology is personal first, philosophical second, and technical last; corollary: understand the philosophy of tech, and see to it that you and the people that make your systems have robust and upright ideas.
Who Owns and Runs the Internet?
As seems to be the theme: there’s a good deal of confusion about who owns and runs the internet, and our intuitions can be a little unhelpful because the Internet is an odd creature.
We have a long history of understanding who owns physical objects like our computers and phones, and if we don’t own them fully, have contractual evidence as to who does. Digital files can be more confusing, especially if stored in the cloud or on third party services like social media. See this piece’s counterpart on freedom for my call to control and store one’s own stuff.
That said, a great deal of the Internet, in terms of software and conceptually, is hidden from us, or at least shows up in a manner that is confusing.
The overall picture looks something like this (from the Internet Engineering Task Force):
“The Internet, a loosely-organized international collaboration of autonomous, interconnected networks, supports host-to-host communication through voluntary adherence to open protocols and procedures defined by Internet Standards.”
Hardware
First, the hardware. Per its name, the Internet interconnects smaller networks. Those networks—like the one in your home, an office network, one at a university, or something ad hoc that you set up among friends—are controlled by the uncountable range of individuals and groups that own networks and/or the devices on them.
Don’t forget, of course, that the ownership of this physical hardware can be confusing, too: it’s my home network, but ComCast owns the router.
Then you have the physical infrastructure that connects these smaller networks: fiberoptic cables, ADSL lines, wireless (both cellular and WISP setups) which is owned by internet service providers (ISPs). Quite importantly, the term ISP says nothing about nature or organizational structure: we often know ISPs as huge companies like AT&T, but ISPs can be municipal governments, non-profits, small groups of people or even individuals.
Don’t assume that you have to settle for internet service provided by a supercorporation. There may be alternatives in your area, but their marketing budgets are likely small, so you need to look for them. Here are some information sources:
- Community Networks provides a list of community networks in the USA.
- StartyourownISP.com does what it says in the domain name.
- This piece in the Electronic Frontier Foundation provides a nice primer.
ISPs have many different roles, and transport data varying distances and in different ways. Put it this way: to get between two hosts (e.g. your computer and a webserver) the data must transit over a physical connection. But, there is no one organization that own all these connections: it’s a patchwork of different networks, of different sizes and shapes, owned by a variety of organizations.
To the user, the Internet feels like just one thing: we can’t detect when an Internet data packet has to transition between, say, AT&T’s cabling to Cogent Communications’—it acts as one thing because (usually) the ISPs coordinate to ensure that the traffic gets where it is supposed to go. The implication of this (which I only realized upon starting research for this article) is that the ISPs have to connect their hardware together, which is done at physical locations known as Internet exchange points, like the Network Access Point of the Americas, where more than 125 networks are interconnected.
Intangibles
The proper function of the Internet relies heavily on several modes of identifying machines and resources online: IP addresses and domain names. There are other things, but these are the most important and recognizable.
At the highest level, ICANN manages these intangibles. ICANN is a massively confusing and complicated organization to address, not least because it has changed a great deal, and because it delegates many of its important functions to other organizations.
I’m going to make this very quick and very simple, and for those who would like to learn more, see the Wikipedia article on Internet governance. ICANN is responsible for three of the things we care about: IP addresses, domain names, and Internet technology standards; there’s more, but we don’t want to be here all day. There must be some governance of IP addresses and domain names, if nothing else so that we ensure that no single IP address is assigned to more than one device, or one domain name assigned to more than one owner.
The first function ICANN delegates to one of several regional organizations that hand out unique IP addresses. IP addresses themselves aren’t really ownable in a normal sense, they are assigned.
The second function was once handled by ICANN itself, now by an affiliate organization, Public Technical Identifiers (PTI). Have you heard of this organization before? It is very important, but doesn’t even have a Wikipedia page.
PTI, among other things, is responsible for managing the domain name system (DNS) and for delegating the companies and organizations that manage these domains, such as GoDaddy, VeriSign and Tucows, etc. I might register my domain with GoDaddy, for example, but, quite importantly, I don’t own it, I just have the exclusive right to use it.
These organizations allow users to register the domains, but PTI itself manages the very core of the DNS, the root zone. The way DNS works is actually rather simple. If your computer wishes, say, to pull up a website at site.example.com:
- It will first ask the DNS root were to find the server responsible for the com zone.
- The DNS root file will tell your computer the IP address of the server responsible for com.
- Your machine will then go to this IP address and ask the server where to find example.com.
- The com server will tell you where to find example.com.
- And, finally, the example server will tell you where to find site.example.com.
You might have noticed that this is rather centralized; it’s not fully centralized in that everything after the first lookup (where we found how to get to com) is run by different people, but it’s centralized to the extent that PTI controls the very core of the system.
Fundamentally, however, the PTI can’t prevent anyone else from providing a DNS service: computers know to go to the official DNS root zone, but can be instructed to get information from anywhere. As such, here are some alternatives and new ideas:
- GNS, via the GNUNET project, which provides a totally decentralized name system run on radically different principles.
- Handshake, which provides a decentralized DNS, based on a cryptographic ledger.
- OpenNIC, which is not as radical as GNS or Handshake, but which, not being controlled by ICANN, provides a range of top-level domains not available via the official DNS (e.g. “.libre” which can be accessed by OpenNIC users only).
The Internet Engineering Task Force (IETF) handles the third function, which I will explore in the next section.
Before ICANN, Jon Postel, mentioned above, handled many of these functions personally: on a voluntary basis, if you please. ICANN, created in 1998, is a non-profit: it was originally contracted to perform these functions by the US Department of Commerce. In 2016, the Department of Commerce made it independent, performing its duties in collaboration with a “multistakeholder” community, made up of members of the Internet technical community, businesses, users, governments, etc.
I simply don’t have the column inches to go into detail on the relative merits of this, e.g. which is better, DOC control or multistakeholder, or something else? Of course, there are plenty of individuals and governments that would have the whole Internet, or at least the ICANN functions, be government controlled: I think we ought to fight this with much energy, because we can guarantee that what any government with this level of control would use it to victimize its enemies.
I think I’m right in saying that in 1998 there was no way to coordinate the unique assignment of IP addresses and domain names without some central organization. Not any more: Handshake, GNUNET (see above) and others are already pioneering ways to handle these functions in a decentralized way.
Dear reader, you may be experiencing a feeling somewhat similar to what I felt, such as when first discovering that there are alternative name systems. That is, coming upon the intuition that the way technology generally is set up today is not normal or natural, rather that it done by convention and, at that, is one among many alternatives.
If you are starting to feel something like this, or already do, I encourage you to cultivate this feeling: it will make you much harder to deceive.
Standards
The Internet is very open, meaning that all you need, really, to create something for the Internet is the skill to do so; this doesn’t mean you can do anything or that anything is possible (there are legal and technical limitations). One of the many results of this openness is that no single organization is responsible for all the concepts and systems used on the Internet.
This is not unlike how, in open societies, there is no single organization responsible for all the writing that is published: you only get this sort of thing in dictatorships. Contrast this, for example, to the iPhone and its accompanying app store, for which developers must secure permission in order to list their apps. I, unlike some others, say that this is not inherently unethical: however, we are all playing a game of chose your own adventure, and the best I can do is commend the freer adventure to you.
There are, however, a few very important organizations responsible for specifying Internet systems. Before we address them, it’s worth looking at the concept of a standards organization. If you’re already familiar, please skip this.
- What is a standard, in this context? A standard is a description of the way things work within a particular system such that, if someone follows that standard, they will be able to create things that work with others that follow the standard. ASCII, USB, and, course, Internet Protocol, are all standards.
- Why does this matter? I address this question at length in this piece’s counterpart on freedom; put simply, standards are like languages, they facilitate communication. USB works so reliably, for example, because manufacturers and software makers agree to the standard, and without these agreements, we the users would have no guarantee that these tools would operate together.
- Who creates the standards? Anyone can create a standard, but standards matter to the extent that they are adopted by the creators of technology and used. Quite commonly, people group together for the specific purpose of creating a standard or group of standards, sometimes this might be a consortium of relevant companies in the field (such as the USB Implementers Forum) or an organization specifically set up for this purpose, such as the ISO or ITU. Other times, a company might create a protocol for its own purposes, which becomes the de facto standard; this is often but not necessarily undesirable, because that firm will likely have created something to suit their own needs rather than those of the whole ecosystem. Standards like ASCII and TCP/IP, for example, are big exceptions to the popular opprobrium for things designed by committees.
In the case of the Internet, the main standards organization is the Internet Engineering Task Force (IETF), you can see their working groups page for a breakdown of who does what. Quite importantly, the IETF is responsible for specifying Internet Protocol and TCP, which, you will remember from above, represent the core of the Internet system.
The IETF publishes the famous RFC publication that I have referenced frequently. The IETF itself is part of the Internet Society, a non-profit devoted to stewarding the Internet more broadly. Do you care about the direction of the Internet? Join the Internet Society: it’s free.
There are other relevant standards, far too many to count; it’s incumbent upon me to mention that the World Wide Web Consortium handles the Web, one of the Internet’s many mistaken identities.
Nobody is forcing anyone to use these standards; nor is the IETF directly financially incentivized to have you use them. Where Apple makes machines that adhere to its standards and would have you buy them (and will sue anyone that violates its intellectual property), all the Internet Society can do is set the best standard it can and commend it to you, and perhaps wag its finger at things non-compliant.
If I wanted to, I could make my own, altered version of TCP/IP; the only disincentive to use it would be the risk that it wouldn’t work or, if it only played with versions of itself, that I would have no one to talk to. What I’m trying to say is that the Internet is very open, relative to most systems in use today: the adoption of its protocols is voluntary, manufacturers and software makers adhere to these standards because it makes their stuff work.
There is, of course, Internet coercion, and all the usual suspects re clamoring for control, every day: for my ideas on this subject, please refer to this piece’s counterpart on freedom.
Conclusion: We Need a Civics of Computer Networks of Arbitrary Size, or We Are Idiots
I propose a new field, or at least a sub-field: the civics of CNASs; which we might consider part of the larger field of civics and/or the digital humanities. Quite importantly, this field is distinct from some (quite interesting) discussions around “Internet civics” that are really about regular civics, just with the Internet as a medium for organization.
I’m talking about CNASs as facilitating societies in themselves, which confer rights, and demand understanding, duties, and reform. And, please, let’s please not call this Internet Civics, which would be like founding a field of Americs or Britanics and calling our work done.
So, to recapitulate this piece in the CNAS civics mode:
- The subject of our study, the Internet, is often confused for the Web, not unlike the UK and England, Holland and the Netherlands. This case of mistaken identity is instrumental because it deceives people as to what they have and how they might influence it.
- The Internet is also confused for the class of things to which it belongs: computer networks of arbitrary scale (CNAS). This is deceptive because it robs us of the sense (as citizens of one country get by looking at another country) that things can be done differently, while having us flirt with great fragility.
- The Internet’s founding fathers are much celebrated and quite well known in technical circles, but their position in the public imagination is dwarfed by that of figures from the corporate consumer world, despite the fact that the Internet is arguably the most successful technology in history. Because of its obscurity, there’s the sense that the Internet’s design is just so, normal or objective, or worse, magical, when quite the opposite is true: the Internet’s founding fathers brought their own philosophies to its creation; the proper understanding of any thing can’t omit its founding and enduring philosophy.
- The Internet’s structure of governance, ownership and organization it so complex that it is a study unto itself. The Internet combines immense openness with a curious organizational structure that includes a range of people and interest groups, while centralizing important functions among obscure, barely-known bodies. The Internet Society, which is the main force behind Internet technology, is free to join, but has only 70,000 members worldwide; Internet users are both totally immersed in it and mostly disengaged from the idea of influencing it.
As I say in this piece’s counterpart on freedom, the Internet is a big, strange, unique monster: one that all the usual suspects would have us carve up and lobotomize for all the usual reasons; we must prevent them from doing so. This means trading in the ignorance and disengagement for knowledge and instrumentality. Concurrently, we must find new ways of connecting and structuring those connections. If we do both of these things, we might have a chance of building and nurturing the network our species deserves.
2 thoughts on “What Is the Internet? (the Future of Coordinated Thinking Pt. 2)”
Comments are closed.