This is the origin story of Coeus, and an explanation of what it is and why it’s worth building.
Coeus is our app: it’s based on the idea that users should be able to create using simple primitives that let them set up, categorize and build information structure as freely as possible. One of the first benefits of this approach is that we will be able, finally, to break down the boundaries between the various apps within the office productivity space. Read on to learn more about the problem, and our solution.
Table of Contents
- Introduction: The Problem
- Understanding the Landscape
- The Problems This Causes
- So, What Do We Do About It?
- The Particulars
- Integration
- A Distributed Unitary Database
- Storage
- Conclusion
Introduction: The Problem
Today’s office productivity suites are powerful but disconnected: spreadsheets, documents, email, diagramming and network graph tools, etc. have immense trouble sharing information between them and, as a result, users waste days each year switching among and finding ways to transfer data between apps.
And, perhaps worse, the restrictive interfaces of these systems often trap users into a particular way of expressing information and, therefore, thinking. Most of our computer systems are built on hierarchical or tabular structures, which encourages us to think in hierarchies and tables, or even to assume that the hierarchical and tabular way is the right way to do things.
But, with a little more precision, what does this mean to say that our systems are thus disconnected?
In essence, you can think of an application as a set of functions (e.g. write text, create formula) that operates on a particular structure of data (e.g. a table); what functions are included in the app is arbitrary but, somehow, along the way the main functions of information management: email, document editing, spreadsheets, database, etc. have separate applications with different interfaces, which are usually mutually incompatible and usually use different data structures.
Really, there should be no separate applications: everything should be mutually interoperable and integratable. Rather, users have to switch apps to do different things, and copy and paste data between them, or set up Byzantine systems like Zapier or IFTTT to connect them. (I like Zapier and IFTTT, but they are patches on broken systems, not solutions.)
This is, indeed, an old problem, dating back to Xerox PARC, a research institute run by the famous Xerox company, where our modern conception of computing was born. Jaron Lanier, an instrumental figure in computing, explains during a presentation how he asked during a tour of PARC, “Guys, why are you copy and pasting when you have a network, you can just reference the original data?” He was whisked aside and told, sternly, “We work for a copier company.”
Understanding the Landscape
So, how can we repair things? How can we build a system that combines the features that we are used to considering as separate, and that can reference any consistent data structure (not just its own)? The first step is to form a conceptual understanding of how applications manage data currently. One way is to divide office productivity applications into three categories that help us either:
- Think: come up with ideas, understand things, collaborate
- Inform: explain things and store/organize/categorize information
- Communicate: dialogue with others
These categories are not perfect, but hopefully a helpful foundation. Let’s discuss each in more detail:
Think
Apps for thinking are the freest and the rarest. They allow for unfettered ideation, free-association of ideas and concepts. They are, therefore, usually based on graph theory, which is simply a system wherein you can have things (usually called nodes) and connect the things in any way with links (or edges).
The computer industry has been quite slow and limited in creating apps for thinking, but there are some examples, the Miro being one. Notably, the whiteboard is a physical analog of this category, and the enduring popularity of whiteboarding sessions is a testament to the power of this framework.
Inform
Where Think apps are oriented to help people come up with ideas, Inform apps are for setting those ideas down in a way that is:
- easily digestible
- findable at scale
These apps, therefore, include word processors, databases, spreadsheets, filesystems, etc. They are characterized by two data structures:
- hierarchical (word processors and filesystems)
- tabular (spreadsheets and (most) databases)
These systems can be quite efficient, but often end up as mind prisons, given their fixed structures. For example, almost all documents don’t allow you to have the same paragraph in two headings (no matter how logically sound this placement would be). Spreadsheets, meanwhile, give you two and no more dimensions: what if my idea is three- (or more) dimensional?
Communicate
Most apps built for communication are modeled on human habits like conversation and letter-writing: in conversation, someone can say only one thing at a time and only one person can be heard speaking at once. As a result, they are usually linear and sequential, and when they offer more ways of structuring information, they may it difficult and opaque.
These apps also prioritize speed and immediacy, again, simulating conversation.
Programs in this genre include email generically and of course systems like Gmail and Thunderbird, alongside Slack, Discord, WhatsApp, etc.
As mentioned above, these apps allow the user to create structure in a very limited way: early on, many allowed you to reply to a message once only, giving strictly linear structures. Now, however, some apps allow a structure that is somewhat hierarchical, with Slack threads, multiple replies to a single email, etc.
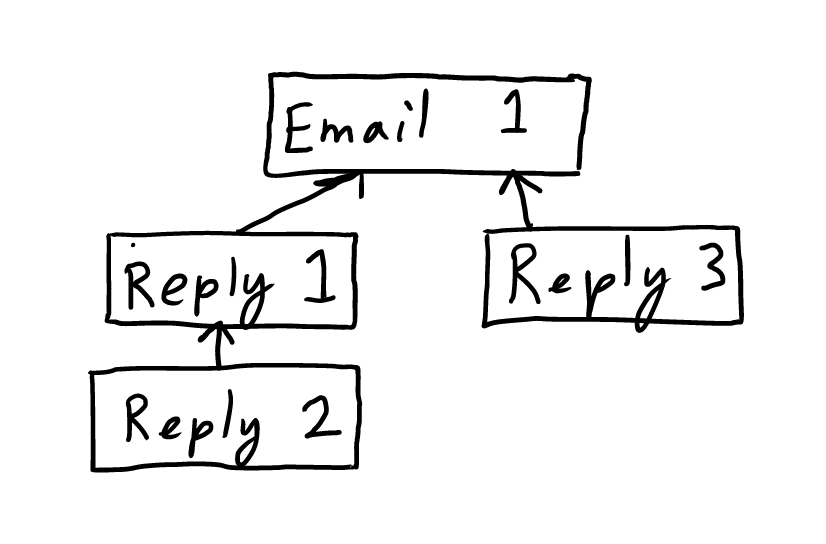
So, to summarize:
- Office productivity software can be categorized as either helping the user to Think, Inform or to Communicate.
- These functions are primarily based on graph theory, tabular structures or hierarchical structures.
- These functions are usually mutually incompatible because their underlying data structures are so different: how could I combine a hierarchical document program with a tabular spreadsheet program?
The Problems This Causes
Application Switching
Because the features we need are separated between apps, we need to switch between apps (often quite frequently and sometimes constantly) when in need of a combination of features. This is obviously annoying, but actually places a considerable time burden on the people doing the work.
Data Transfer
Theoretically, the data should be just there and we the users should be able to access and reference it freely (see Jaron Lanier). Instead, we either have to copy and paste the data (after which point it is “dead” and no longer updated by editing the original) or use labyrinthine tools like IFTTT or Zapier to transfer it automatically (meaning it dies also).
Rigidity
Finally, in each of these specialized applications, one finds oneself in a specialized prison: in documents, one must choose an order for sentences and paragraphs, even if they are equal in order or if there are multiple valid orderings. In a spreadsheet, a given cell can be adjacent to at most four of its compatriots. Put plainly, hierarchical and tabular tools allow hierarchical and tabular data, and not much more. And linear tools are much worse.
As a result, users are frustrated or (worse) come to believe that data is necessarily hierarchical or tabular. But of course we know this is not true: the most interesting data is much more richly interconnected. Indeed, two of the world’s biggest and influential companies are based on network graph data: Google (the network of links between websites) and Facebook (the network of relationships between people).
So, What Do We Do About It?
How can we create a new interface that combines these main three functions: Think, Inform, Communicate, and that allows interoperability of data? I think that the solution will involve adopting a few principles:
- Applications should be as free and generalizable as possible: if the logical premises of the environment permit something, the user should be able to do it.
- Certain limitations on what the user is permitted to do should be built as expedients and not restrictions: for ease and speed of creating tabular data (say a student register) a user may wish to operate in a tabular “mode” that makes creating tabular data fast, but should be able to exit that mode at any time, and annotate with non-tabular data in the margins.
- From the Unix manifesto: “Expect the output of every program to become the input to another, as yet unknown, program.” The data structures we create should be clear, open, and interoperable.
I think that if we adhere to these principles, we’ll design a system and data structure that’s flexible enough to express everything required to Think, Inform and Communicate, and therefore that can perform the fundamentals of the main office suite tools while allowing users to combine and blend currently separate functions and data.
Our system, Coeus, will be based on what I call the hypertructure syntax. Here is a very high level overview of its fundamental components:
| Component | Function | UI |
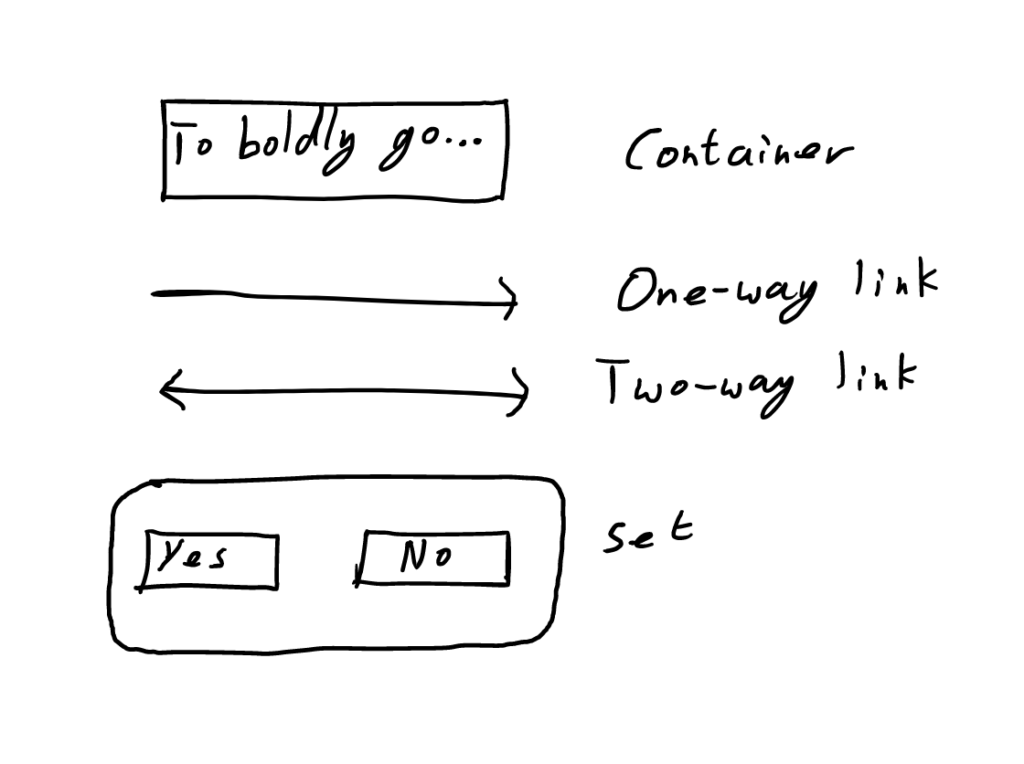
| Node | This is the atomic “thing” in our structure. It can be anything: text, a URL pointing to a webpage, etc.. It has no internal organization apart from the linear flow of text, so users are encouraged to make their nodes as small as possible. | A square box containing text |
| Relationship | Relationships express how nodes and other relationships are structured. A relationship can organize any number of other items. There are two main types: | |
| Link (Type of Relationship) | Links show connections between things; they can be one-way or two-way. This category includes hyperlinks, the connections between items in a network graph, but also the adjacency between cells in a spreadsheet, email replies, etc. | An arrow with one or two heads, connecting the items it organizes |
| Set (Type of Relationship) | Sets group any number of things together, like a file in your file system, a document heading which contains a number of paragraphs, a tag in a database or CRM, etc. | A box with rounded edges, containing that which it organizes |
I hope you will, dear reader, see that these primitives and rules are flexible and generalizable enough for us to use them to create all manner of structures and operations, including and beyond the functions required for Think, Inform and Communicate tools. With this system, the user can forget about file-types and choosing which application they wish to use for a particular task: they can just use Coeus and combine in a single environment all the functions they need.
The Particulars
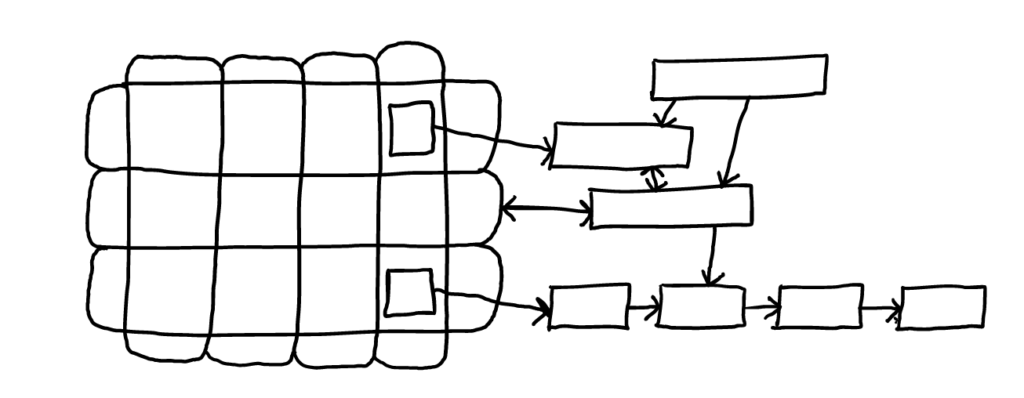
Here is a breakdown of how Coeus will achieve the main modes required of it. The principle of operation is one of filtering and arrangement: for each mode, a different filter is placed on which relationships are shown (e.g. show me only tabular data) and the contents of the user’s setup are arranged and juxtaposed differently.
In Think mode, everything is one type; in the other three modes, Inform: Hierarchy, Inform: Table and Communicate, the filtered material is shown and arranged in the middle of the screen; the user can chose either to omit material not filtered, or show it on the edges. Thus we can have a document-like structure in the middle of the screen, with arbitrary notes on the edges.
Mode 1: Think
The freely manipulable Think mode is perhaps the most natural to Coeus: users can create nodes and associate them freely and to any level of depth: network graphs, mindmaps, hypergraphs; links to links, sets of sets, links to sets, etc. etc.
On screen, the material will be arranged to show the information most clearly: with as little overlapping as possible; the user can choose a focus item to hold at the center of the screen, filter, rotate, etc.
Mode 2: Inform: Hierarchy
Ted Nelson said that good writing is about editing, and that good editing is about rearranging. Most current word processing systems are quite functional, but make it difficult to rearrange text because you can’t pick up and move sections with much ease.
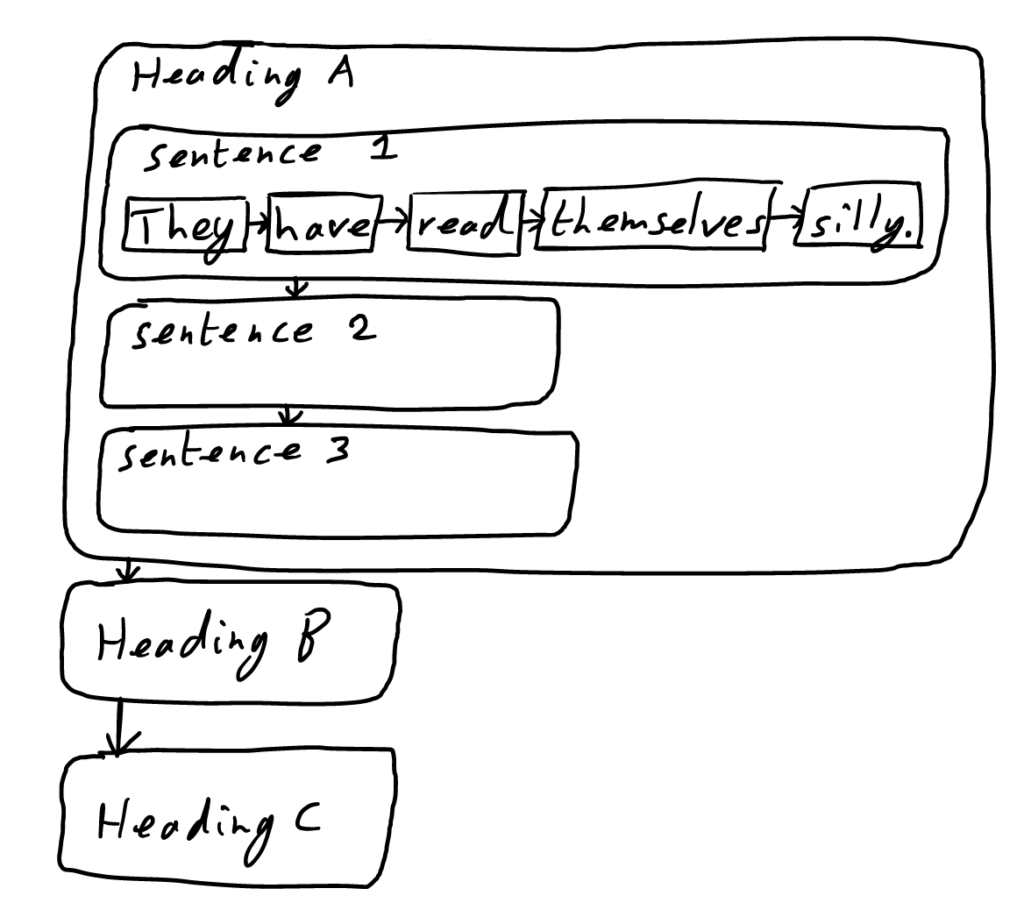
In Coeus, everything is stored in discrete nodes, organized in nested sets, and with the order determined by directional links. So, for example, each word in a sentence would be a node, each sentence would be a set, these sentence sets would fit into a paragraph set, and these paragraph sets into a set for a subheading, these subheading sets into a major heading set, etc.
Each word links to the one following it with a directed link, and each paragraph to the next, each heading to the next, and so on.
The user can, therefore, easily select and re-arrange the order of things, putting one paragraph before the other or moving items in and out of a heading. This is not copy or cut and pasting, this is rearranging*.
As with normal documents, the first thing comes first, whichever the cultural norm (top left in English, flowing downward). It will be possible, also, to have truly unordered sections, such as a section in a document consisting of three sentences with no links between them: meaning that none of them comes first. One can have, also, several sections that all come next, equally, i.e. all are linked to what precedes them.
This is obviously more complex than a conventional word processor, but it will be no more complex to use; as the user types, Coeus automatically creates nodes, sets up links, creates nested sets for paragraphs, sentences, etc. The user only needs to be aware of them when they require them.
Fundamentally, because everything is stored as nodes, sets and links, we can access documents created in Inform: Hierarchy mode in other modes. For example, in Think mode, you can include pieces of your document in a network graph. Again, this is not copy-pasting, it is rearranging.
Mode 3: Inform: Table
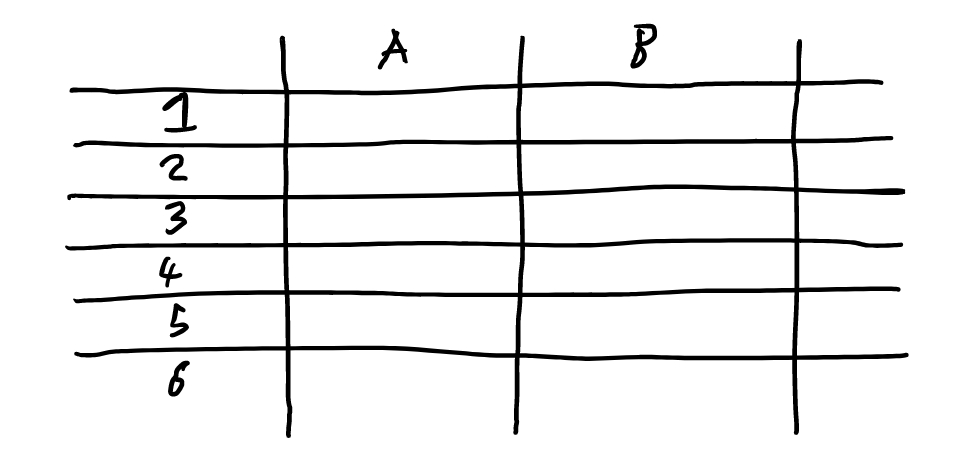
Inform: Table mode is designed to give people features associated with tables, spreadsheets and databases (both relational and non-relational) and even n-dimensional arrays, which are compatible also with the other modes.
This is achieved through specially identified sets: for a spreadsheet, Coeus creates a set for each of the columns (A, B, C, etc.) and for each of the rows (1, 2, 3, etc.) if something (a node, a set, anything) is in one of these sets, it is in the relevant column or row. If something is in a particular row set and column set, it is therefore in the relevant cell.
The user can do many of the normal spreadsheet functions, like filtering, sorting, re-arranging, etc. And, Because of the freedom of the Coeus setup, users can do things not possible in spreadsheets, like drag and drop things between cells, have more than one uniquely identified thing in a given cell, or a given thing in more than one cell.
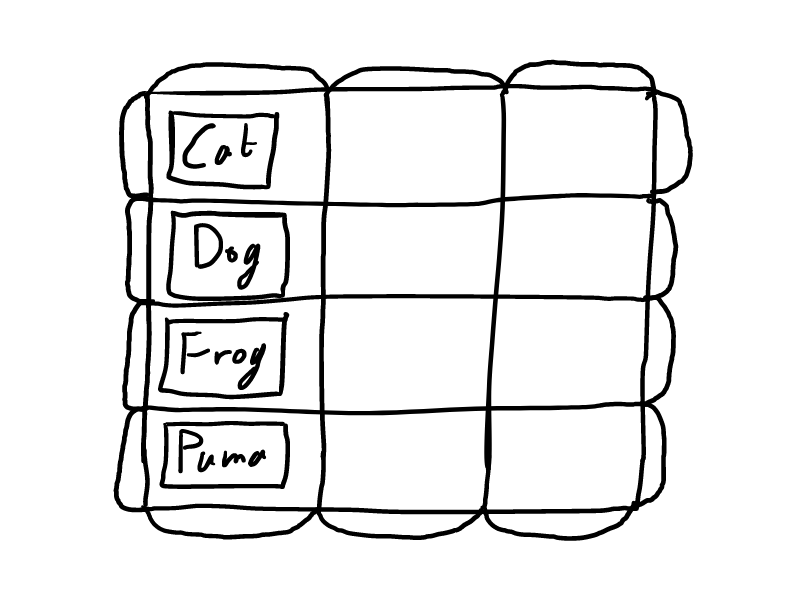
As with Inform: Hierarchy mode, the user can create information on the edges that would otherwise be filtered out, such as for making marginal notes or comments.
Using two dimensions is of course most familiar to us, but there are more options. With one dimension, users can create something like a NoSQL database: with a set for each unique ID, the contents of the set can be anything: a node with text, a graph, a tree, etc. Meanwhile, there’s no limit on the number of dimensions users can create, meaning that 3-, 4-, 5- and more dimensional arrays are possible.
Again, anything created in Inform: Table mode is interoperable with all other modes: one can have a fully-fledged document inside a cell in a table; the contents of a table cell can be included as a sentence in a document.
Mode 4: Communicate
The idea of Communicate mode is to give the user everything they need to communicate quickly and seamlessly while integrating with the other Coeus modes. Email, Slack, etc. are (usually) fast and work OK, but they really are where information goes to die: we require a system that is as quick and conversational as Slack and email, but that allows for the organization, categorization and arrangement of the information transmitted via our conversations.
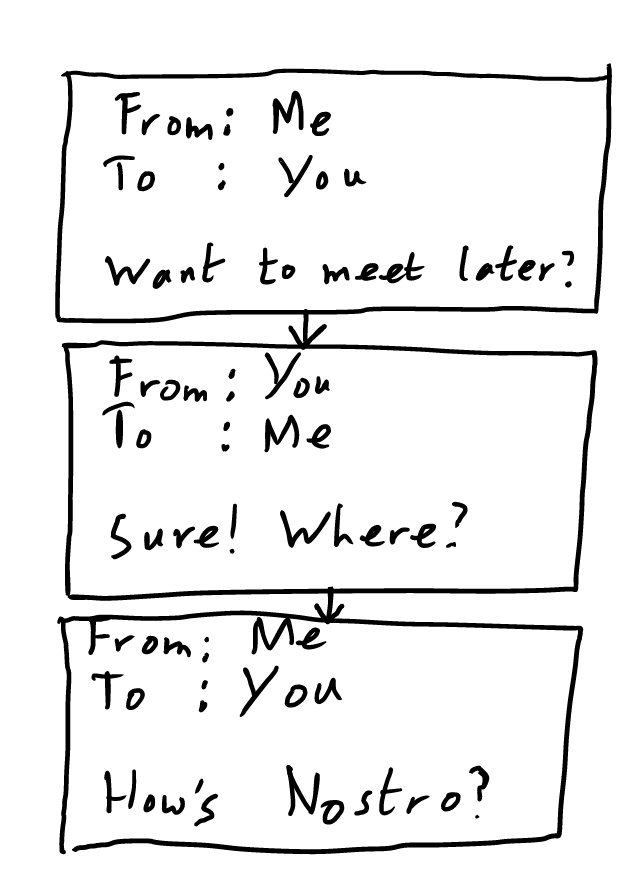
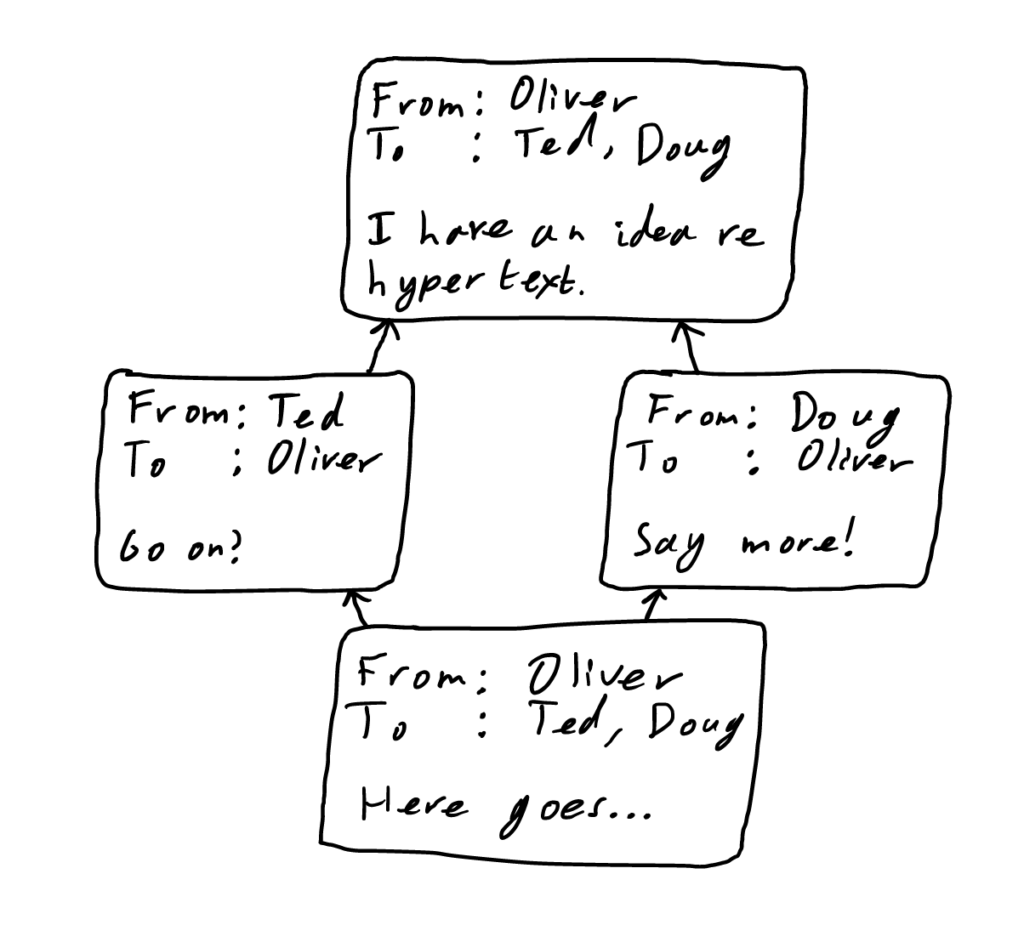
Communicate mode is very similar to Inform: Hierarchy mode: a message is a set containing the requisite sentences and other necessary information (send time, subject line, as applicable). Replies are directed links, so if I reply to your message, I create a new message set with a directional link pointing to your message.
This allows for numerous benefits not afforded us currently:
- We will be able to visualize our conversations as they really are: branching trees.
- With the freedom of Coeus, it’s possible to reply with a single message to more than one message at a time: something conceptually valid but currently impossible with email.
Communicate mode in Coeus will be so immensely better than email, Slack, etc. that people will likely give up on these tools, or use Coeus as their backend. In the meantime, we will build integrations for users to use Coeus Communicate to send messages via their Slack/Gmail, etc. from the Coeus interface.
Again, at risk of sounding repetitive, everything in Communicate is interoperable with other modes, with the exception of editing a message that has already been sent (we can overlay edits atop the original, however). Thus, a user can include an email conversation in a document (not copy and pasted, actually referenced), or might use it as a document outline and build around it, or can take a paragraph from a document and send as a message.
Integration
Coeus means the end of separate and non-interoperble, “siloed” apps, requiring you to switch and copy data between them. Every node, set and link will be available and freely integrateable. Integration is of course an odd choice of word, indeed before we came to integrate these things they were first disintegrated; we are re-integrating what used to be a unity: data.
See Ted Nelson’s TED talk from 1990 below to see how long we’ve been grappling with this problem.
Coeus ends the phenomenon of app switching, and of users wasting time copying data and of their data dying after it is copied: everything is available and everything is alive. It is, as Nelson demands, a “tapestry of capabilities and work circumstances that is a unified whole.”
Beyond this, there are just two additional parts to complete the picture:
A Distributed Unitary Database
I won’t go into the details of the syntax through which this information is stored here (but I will elsewhere). It’s important to address, however, the question of how and where data is stored. In the above discourse, we addressed things from the perspective of an omnipotent user who could see all data: of course, Coeus is most life-changing when used as a collaborative system, used over the Internet via individual users, users in collaboration, and those working within and among organizations.
One of the key functions within a system like this will be the ability to adapt, re-use and structure things other people have created (with the necessary permissions). For example, I might wish to collaborate on a mind-map with hundreds of other participants in a Wikipedia-style endeavor.
At this point, data management becomes a problem: when I look at a given thing, such as a node, I want to see how it fits into the bigger picture; I want to see the links two and from it. Now, if all users store their own links, I’d have to query each individual user’s instance to see all the links. Conversely we could store all the structure in a single database, which would be too much power for the individual in control of the database.
You will, dear reader, probably have realized that the Web is an odd blend of the above: each user is responsible for their own links, so nobody really knows what links to what; Google has built a database of a lot of the links, and Google has far too much influence over how we find information as a result.
I propose a third way: we have a single database, but we share it using distributed ledger technology. Just as bitcoin and other cryptocurrencies use a distributed ledger to describe the balances and transactions within their systems, Coeus will use a distributed ledger of links and sets: any user can publish a set, link or combination thereof, which will then be percolated among participating users.
The content itself, however, should always be stored on users’ own servers, as it’s foolish to put content on the blockchain: we should be able to delete our teenage social posts. We call this database the
“Hypercosm.”
Storage
Finally, there is the issue of content storage: just as Google has too much influence because it stores all the links, Facebook and other platforms have too much power from hosting all that material, images, writing, ideas, etc. More intelligent people than me have expressed this better than I can here, but I’ll make just two points:
- Facebook and other platforms filter material and manipulate how it is shown without showing us how. It’s their platform and their right to do so, but people deserve an alternative.
- If it’s not on your server, it’s not your content: dictatorial regimes are known to pressurize social media platforms to take down material offensive to them; Facebook and similar platforms are single points of failure for this.
We propose, therefore, that people store their content on their own servers, and we will provide an easy, affordable solution for them to do so. We call this solution Envoy, which is simply a virtual private server uniquely identified with a domain name, and running the necessary software to participate in the Hypercosm distributed ledger.
Conclusion
This is the Coeus vision, therefore: for users control their content, for users to control how they experience their own and others’ content, and for us to build collaboratively a commonly-owned fabric of information structure. With Coeus and collaborating in this way, we the users will finally have a system with the fidelity necessary to solve the complex, chaotic problems that confront us: environmental destruction, inequality and rapid technological change.
*In some sense, this is cut and pasting; Nelson explains how on paper, cut and pasting means literally to cut a manuscript into pieces and re-arrange it, which is much better than what we call cut/copy and paste today.