Why URLs are the best of the Web, and why, despite this, their limitations are the limitations of most modern technology.
The URL is a strange thing: it’s in front of all of us much of the time, but we barely notice; we know how to manipulate its symbols and structure, but few of us know what these things mean. In my opinion, the URL is an example of the vaulting ambition that made the Web successful, but also of the lack of ambition that lead to the dreadful situation where we find ourselves: abundant but disconnected and disorganized information, with huge monopolies that exist solely to help us find things.
In this article, I’m not going to spare the technical details, but I am going to do my best to explain things clearly. If I err or am not clear, please reach out or leave a comment!
Why URLs?
First, why do URLs exist? At base, they exist to help us people to find things on different computers.
But what does this mean? Well, most readers will be familiar with how different hardware and software types, e.g. iOS, Linux, Windows, etc. address data on their storage differently: on Linux it’s /home/oliver/, while on Windows it’s C:\\Users\Oliver. Different computer systems use different methods, protocols, languages, etc. to access information.
As such, it’s impossible for one computer to know how to find things on most other computers, and definitely not all other computers. URLs are a means of making information accessible among these different machines. The user can simply enter “https://olivermeredithcox.com/about” into their URL box in their browser and not worry about what operating system, version, etc. the computer that will respond to the query is running: that all gets handled on the other end. You might, dear reader, forget that there is even another computer on the other end, responding to your request.
A brutally crude comparison would be to Google Maps: each country has its own system of roads, signs, etc. but Google Maps applies more or less everywhere and can guide or even navigate you between borders. In the same way, URLs are mapped to data on computers; if you load one in your browser, it will take you there.
The Anatomy of a URL
The URL itself is a confusing construct — combining several different systems and approaches to information — and comes in three parts:
- The protocol, e.g. “https” followed by “://”
- The domain name, e.g. “hyperstructure.media”
- The path, e.g. /about
Part 1 is pretty simple: we’re just telling the computer that loads the URL what system to use, e.g. https for the Web, mailto for email, etc.
Part 2, the domain name, is a little bit more complex and somewhat bizarre. Domain names are human-readable identifiers for computers, networks and services online. Every computer online is given a unique IP address, but for most people these change not infrequently; the domain name, which may never change, is a more stable and memorable way to find what you’re looking for.
How does this work? Let’s say we’re seeking hyperstructure.media: the first step is to go to the DNS (domain name service) root and ask, “where can I find ‘media’?” The DNS root servers are responsible for the very top of the DNS system, a tree of all the domain name information. The root at the top, beneath which are the top level domains like com, net, media, etc., beneath which are the domains that people like you and I buy, e.g. hyperstructure.media, olivermeredithcox.com, etc.
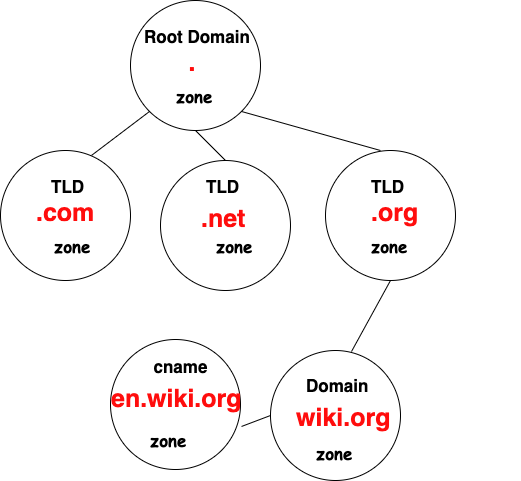
If all goes to plan, the DNS root will give us the IP address of the media server; we ask that server where to find “hyperstructure,” and it should give us the IP address of the server where my website is hosted.
The odd part is that this hierarchical system nests from right to left: the root contains media, media contains hyperstructure — this is the opposite of most foldering systems (e.g. on my computer /home/oliver/documents, means that / contains home, home contains oliver, and oliver contains documents.
This caused my young self much confusion, especially as in the good old days, almost all web addresses began with “www,” making it sound like www was at the top of the pile, with the rest within it.
Part 3 takes over once the device in question has found and is talking to the right server. As you might guess, especially if you use a Mac, Linux, or something else influenced by the UNIX operating system standards, this part of the URL is based on the UNIX filesystem.
On a high level, the idea of the UNIX filesystem is that the operating system creates a hierarchical construct, which contains everything on the system in a set of files and folders. In practice, these folders are separated by “/” and proceed from left to right. So, for “hyperstructure.media/about/team” the folder “team” is inside the folder “about.”
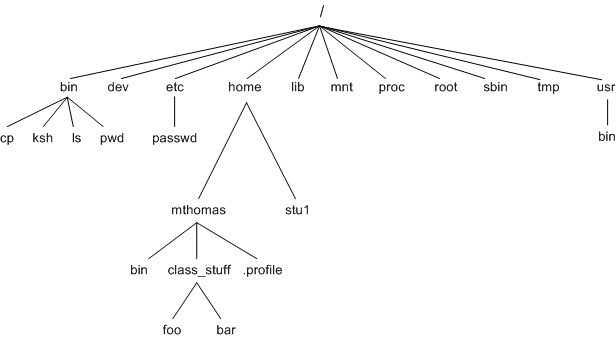
URLs extend this structure online, and gives us a way to address things between computers that may or may not be running UNIX.
Human-Readable, Mostly Unambiguous Signposts
There we have it: URLs are special and interesting not just because they tell our machines how to find things unambiguously, but because they do so simultaneously while providing us the users with some information and context. For example, take the URL on the IBM site: https://www.ibm.com/products/aspera/data-migration. This URL tells us quite clearly that the page to which it will take us pertains to one of IBM’s products, particularly aspera, and the data migration feature of that product.
Not all sites are this explicit, of course, as we’re fairly unconstrained as to what we put in our URLs after the domain. Netflix, for example, arranges its material with URLs such as “https://www.netflix.com/watch/80170696” where the number at the end identifies for the computer which episode to show us, but won’t tell me what episode it is without loading it.
It’s hard, really, to get across what an amazing invention URLs are. Remember that, today, many Mac- and Windows-formatted disks cannot be placed into machines running the other operating system safely or to achieve the desired purpose. Many computer corporations and departments are will always be attempting to build incompatible standards and thereby lock customers into their corporate worlds.
Astonishingly, many organizations would rather create an inferior product, either lacking the ability to connect with others, or would deny others the information necessary to make compatible products–this is to choose, deliberately, worse tools for the sake of profit.
But URLs are different: they, along with the larger Internet ecosystem consisting of email, the broader Web, etc. are open, and so widespread that the normal incompatibility-vendors have no choice but to support the standard.
Limitations
With all this praise, it remains for me to talk limitations.
1. Relationships
The main missing feature of the URL is this: URLs show you where to find things, and tell you a little about the thing and where it is located, but they can tell you practically nothing about the actual relationships between things.
Put it this way: if I put a link on a page from my website to one on your website, we can say that the two pages are related, even that a particular piece of text (shown in blue) is related to the “target” page on your site. But the URLs by themselves can’t express this information: I can use a tool to scan a webpage and make a table of the implicit relationships between it and other pages/sites, but there is no way native to the Web/URLs to do this that is standardized and widely adopted.
What humanity has needed for some time is a way to show these relationships, i.e. a syntax or structure, like that of a URL, which can express that two or more things are related and the nature of the relationship.
Where a URL points to an object, like this:
https://example.com/here/is/my/url
We need a syntax that can show a relationship between any number of things, e.g.
rel://thing1.com/my/thing*link*thing.com/my/other/thing
2. Organization
With the Web, essentially, the assumption is that some level of organization is placed at the end of the URL, e.g. for https://www.ibm.com/products/aspera/data-migration the URL stops after “data-migration” and our browser takes over, in this case presenting the ordered text on the page. This roughly corresponds to the old and bad idea of the “file” in computing.
In essence, a file is a construct in a computer operating system that points to a particular location or several locations in storage where the file’s data can be found. Another way to think about this is to say that the filesystem can arrange and display the structure of files and folders down to the level of individual files and no further. I can find a spreadsheet on my disk with my file browser, but require my spreadsheet program to delve deeper, e.g. to find a particular row or cell.
This is a sad travesty: our computer storage is full of these odd constructs, most of which have fairly trivial internal organization: tables for spreadsheets, tree hierarchies for documents, etc. but they mostly require separate applications to view and understand their structure. The reader will I’m sure have realized that I think it would be much better for our systems to allows us to explore our data down to the bit: I should be able to open my spreadsheet in my file browser and continue exploring.
HTTPS does, however, offers the query command “?” which passes that which follows the “?” to the page for processing, e.g. “https://www.ibm.com/search?q=hello” or the fragment command, “#” which takes you to a place on the page in question marked with the desired ID, e.g. “https://en.wikipedia.org/wiki/URL#History”.
Thus, the assumption here is that there is some level of organization that ought to be the page (akin to a file), above which should be folders (or pseudo-folders in the URL) and beneath which should be queries or “fragments”. In the example above, Wikipedia decided that the URL concept deserves its own article, while the history portion deserves only a fragment.
But what if I want to send someone, unambiguously, to a piece of content (say a heading) and only the content in the heading; or to several pages, concatenated one after the other in one URL, to flow in sequence without navigation? There are few options available to me. (Though some valiant publishers are pushing the boundaries, such as the wonderful online books by Holloway.com, that allow you to link to sections in themselves.)
The trouble here is that our concept of what should or shouldn’t be the web page is arbitrary: URL and URL History are equally valid as pages in themselves. If the choices are arbitrary, the way we view things should be freely mutable and optional. This is to say that the user should be able to view any number of pages together, a single heading, paragraph or even word as a page, if they wish.
So, instead of:
https://en.wikipedia.org/wiki/URL#History
We could use the Web like this:
https://en.wikipedia.org/wiki/URL/History/paragraph-1¶graph-2
This is to say that it’s possible to link directly to paragraph 1 and 2 of the History section, and to link to both of them at the same time (and read one after the other).
Conclusion: Space
Thirty spokes unite around one hub to make a wheel.
It is the presence of the empty space that gives the function of a vehicle.
Clay is molded into a vessel. It is the empty space that gives the function of a vessel.
Doors and windows are chisel out to make a room.
It is the empty space in the room that gives its function.
Therefore, something substantial can be beneficial.
While the emptiness of void is what can be utilized.
Tao Te Ching, Laozi
The above passage from the mystical text the Tao Te Ching reminds us of the importance of space, void, emptiness; it’s often the quantity that gives things meaning or actually make them useful. Space, or more importantly the absence of whatever it is where concerned with, is the interstitial tissue that lets us arrange things in ways that are meaningful to us.
Space is the raw material from which we form relationships: the lines between spreadsheet cells, the gaps between words and paragraphs, the separation of different webpages that are nonetheless linked. This raw material can be formed into anything: links, other relationships, or no relationship at all. Things are meaningless without space.
It comes down to a question of what you do first: do you create things, or in the absence of things to you create, or think about, structure? This is akin to how it took so long for the people of Europe to develop a digit for the number zero; the digit zero (0) is important not just as indicating that there is nothing somewhere, but as giving us a means to form place value, e.g. the “1” in the number 10 means ten, because the “0” to the right is occupying the space for ones In some respects, we can assume there to be a pre-existing, invisible structure of place-value that manifests before we write a single digit. This is challenging for us, because it’s there when we can’t see it.
Conversely, in the case of the World Wide Web and URLs, the first thing that they did was create the page, uniquely identified and reachable via its URL. Then, apparently, they asked the question, “How can we link these pages together?” and they derived the hyperlink (which is just a URL embedded against a string of text in a page). This is to say that the scheme of Web linking is based upon and derived from the objects themselves. In this respect, it is like Roman numerals (which have no digit for zero).
In my view, the proper way to approach this problem is first to ask the question, “How can we structure things? What are the means available to us to arrange objects, and how might we express this information through our machines?”
The way I personally answer this question, which is at the heart of HSM, is to say that our universe should consist of two primitives: things and relationships; things point to lumps of information not organized in our structure, and relationships indicate how any number of things or relationships are related. With this system, you can do everything you can do with the Web, and more. The origin of this greater power is the fact that it is a system of space, or relationships that exist among the things that are related, not within them.
Zero makes us uncomfortable, but if you start with it, you can get places.