We forget at our peril that the medium is the message in software, too; worse, the makers of software are working hard to create this amnesia.
I had a conversation with an angel investor recently and something she said got me thinking about the relationship between the data structures in which we build and the user interfaces of the resulting software. I theorize that the resulting system runs according to Marshall McLuhan’s the medium is the message equation, wherein any message will be bounded by its medium, which includes the interface messages that we build in data structure media.
The Original Contradiction
The other day I was speaking with a fellow entrepreneur who happens also to be an angel investor. We each explained how our systems worked; hers is a data analytics system with some very interesting capabilities and assumptions.
I asked whether she felt as though Hyperstructure Syntax might be of use to her system, because the Syntax offers a flexibility of information structure that I think lends itself to the sort of semantic processes she talked about. My asking was a mistake: Ted Nelson explains quite vividly in Computer Lib how computer people are surprisingly cold with respect to the cherished ideas of others (I admit to being cold, also, but am working on it. It can be a special affront to hear it suggested that one might combine my ideas with yours).
Her response in the negative was interesting, however, for expressing one of the main contradictions inherent in how we think about data and information technology: she said that my Hyperstructure Syntax was unnecessary because you can express more complex or richly interconnected structures using tables, and, besides, it’s actually useful to get people to create their data in restrictive formats because it increases compatibility because users/programmers don’t build anything too weird.
I’ll examine both clauses of her statement in detail, but it’s first worth exploring the contradiction in what she said; making it a little fruitier:
- We don’t need Hyperstructure Syntax because we can do that complex stuff in tables.
- Tables are great because they encourage people not to do all that complex stuff by making it hard.
This is the text and subtext of modern computing conceit: we don’t need your newfangled freedom because you can do anything in our system, and, besides, we like our system because it is difficult enough to do weird stuff, so people give up. This attitude is at base the desire to restrict things that are complex and difficult, beneath a layer of chauvinism, disguised as technological pragmatism.
For the uninitiated, see visual examples of hierarchies and tables below, the sort of structure which my conversational partner thought was the best we needed:

{kind=link}
{kind=link}
These data structures are quite fast and useful, but intensely restrictive. You can read more about our vision for structure here at HSM in our article Think, Inform, Communicate. The drawing below depicts the sort of structures possible using the Hyperstructure Syntax:
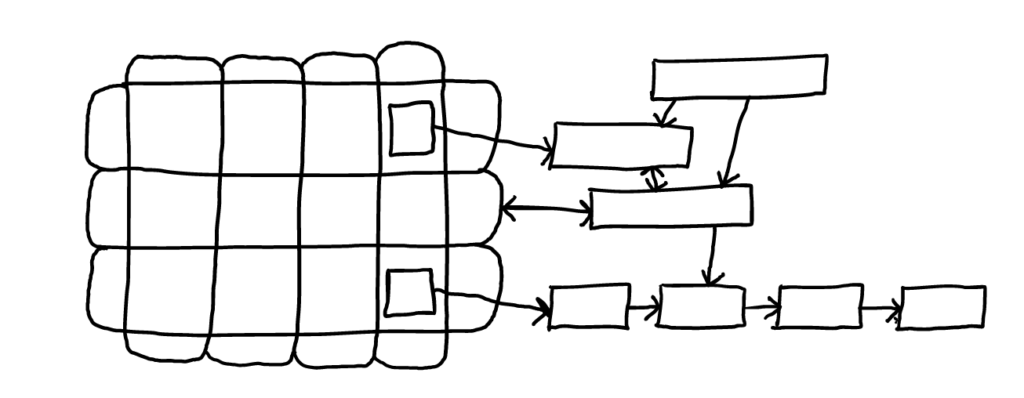
People, especially certain types of programmer and technologist, fear and intensely dislike the irregular and the intensely free: they shun the network graph, hypergraph or even the loop in favor of the table and the hierarchy. But the table and the hierarchy are with us only because of paper-based information management and physical filing systems: one piece of paper can go in one and only one folder, and a field in a two-dimensional table can be next to at most four neighbors; we re-created these restrictions in computers.
I consider the filing system of tables and hierarchies a mere accident or blip: it just happened that these restrictive systems were the first we developed and now we’re stuck with them. I’m reminded of a radio interview in which a home cook was asked why she chopped off the legs of her chickens before roasting them together with the rest of the bird; she didn’t know why, but her mother did it that way. The crew tracked down her mother, who explained that she chopped off the legs so as to fit the chicken in her diminutive pan. Her daughter, who had a pan large enough for turkey, carried on a tradition divorced from the restriction that birthed it.
Restrictions for Compatibility’s Sake
So, let us discuss the first part of her claim: the idea that restrictions on data structure are helpful for getting users to create data that is compatible. This is quite true, but not really in the way she meant: in truth, forcing users to create their data in a tabular format maintains easy compatibility with existing tabular systems.
Really, all that’s required for compatibility of more than one database or data structure is some correspondence between required fields. This is possible whatever data-structure one is using, possibly given some clever stuff in the middle.
I have another proposal: we should all use data structures that are maximally expressive (giving users unlimited ability to organize and associate data) and finely addressable (the smallest atomically sensible data should be addressable). With such a mode of organization, we can recover the required structure for any compatible database.
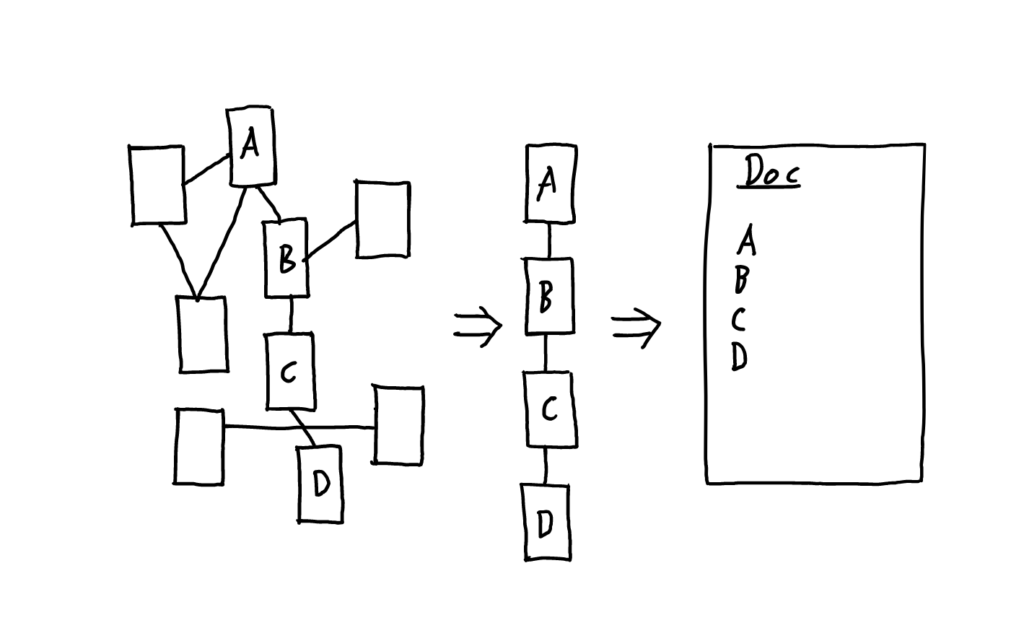
To put it plainly, the Hyperstructure Syntax is based on the principle that we should be able to create things, and associate those things in arbitrary ways, including building relationships among the relationships, and so on. Relationships can be links (which connect things) and sets ( which group things together). I can create a set of things, a set of links, a link between several sets, etc.
From this system is is trivial to recover everything that we can do with tables. For example, we can create a certain category of set for “person record”, say, and identify this with the a row in relational database describing people. We then simply match the data-points from the “person” sets to the rows in the “people” database.
Agreement Rather Than Restriction
This is not sufficient of course to establish interoperability between databases: the users/maintainers of the databases need add the required data and do so correctly. For example, it might be important for a particular application to have separate given name, family name and title fields, e.g. Samuel, Johnson, Dr.
It may be tempting to assert, by extension, that there is just one way to express your data, and force users to do it your way. At HSM, however, we think limitations on what we can do in particular circumstances may be warranted or useful, but we should never force these limitations or otherwise pretend that they are the way things should be.
Tabular structure, hierarchical structure, even linear structure can all be useful and save time—for example, spreadsheet functions like selecting a row of formulae and dragging down to populate a number of rows below with contextually updated formulae isn’t possible in non-tabular data. But to do this you only need a particular piece of data to be tabular and to identify it as such. It can be a piece of tabular data in a sea of non-tabular data.
But most of our software doesn’t take this approach, it is rather based on a set of unspoken assumptions (a file can be in at most one folder, a spreadsheet cell can be adjacent to at most four others, a sentence follows one and precedes another) that are sometimes convenient but rarely actually necessary and are sometimes quite contradictory. These restrictions are baked into software and thus become very hard to escape.
It shouldn’t be this way: we should communicate with users about what they stand to gain and lose by adopting or shunning different structure, and invite them to take certain actions and limit how they do things if they wish; e.g. a user may wish to ensure that each person in their Hyperstructure database is enclosed within a set, so as to maintain compatibility with tabular systems. Limitations like this should be vocal and voluntary, i.e. they should be unambiguously identified and entered into voluntarily; the user should determine to what data the restriction in question applies.
So, the industry appears to be saying: “We think that you can’t be trusted to arrange your data in a compatible way, so you must build your database in our way.”
We say: “You can build your database as you wish, but if you wish to maintain compatibility with our database, then consider arranging your data thus.”
On What Level of Abstraction Should We Allow for Freedom?
To return to the angel investor’s contradictory statement, I should note that it contains within it the fundamental germ of computing discussion: she said that we don’t need Hyperstructure because you can do everything in tables, but also that it’s good to use tables because they keep people from creating weird incompatible data structures. Said another way, “It’s theoretically possible to create anything in a table, but it’s fiddly and unpleasant enough to prevent those pesky artists from breaking too far out of the system.”
Again, this is quite true, the appropriate question however isn’t of what’s possible in a given system, but of what is natural.
Put simply, what is natural in our systems will be done and repeated again and again: it affects how we think and causes us to create it anew in existing technology. People even start to believe that things are impossible because they’re not done: when I first heard Ted Nelson say that there’s no reason today why a filesystem shouldn’t allow a file to exist in more than one folder, I thought it was madness. Tables and hierarchies are actually quite unnatural: networks and richly nested structures are more common in nature: see social networks, food webs, ant colonies, the brain, etc.
Let’s consider what this means precisely for a moment. We can think of computing as consisting of three layers: hardware, build-focused and use-focused. (This is obviously not the only reasonable layering scheme.) In the use-focused layer we find those things that are most familiar to us: applications, user interfaces, constructs; only what is permitted is possible. In the build-focused layer we find programming languages, data structures, databases, protocols etc.—the set of formal systems that powers the level above and determines what is permitted.
Beneath that is the computer itself. Simplifying somewhat, the computer level operates as a single stream of operations, one thing at a time, one following that last. (It’s a little more complex than this, e.g. many processors have multiple cores that operate in parallel, each core however is purely linear.)
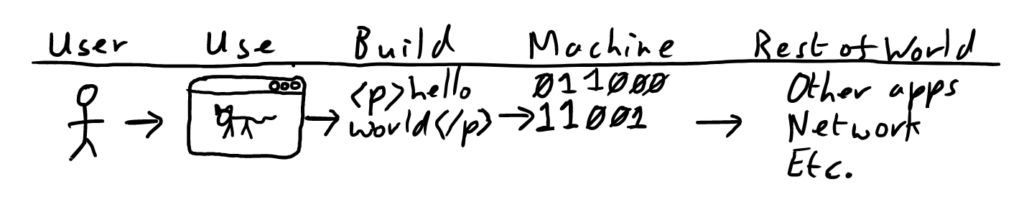
This is to say that, to be computed, eventually everything has to be expressed as a one-dimensional stream of data. A good analog of this on the user level is the CSV file. A spreadsheet program works in 2-D, but you can export to a text CSV file which expresses the sheet as a linear plain text file, with cells separated by commas and carriage returns to rebuild the table.
Everything in our computer world: documents, databases, images, graphs, tables, hierarchies are all at least once expressed as a linear stream. Now, feeling something of le espirit de escalier, I wish I had said to the investor, “Indeed, you can actually recover all of computing from a one-dimensional data-stream, so why don’t we just do that and do away with tables?”
Indeed, there are esoteric programming languages that operate in just this way, though primarily as a mental exercise and a curiosity. For example, Brainfuck assumes 1. a one-dimensional array of memory cells, 2. a pointer that can focus on any of the cells, and 3. the ability to increase or decrease the value of the cell and, finally, 4. the ability to move the pointer in one of the two directions on the one-dimension of the array. Brainfuck, it’s important to note, is Turing complete (it almost is a Turing machine) meaning that it can simulate any computer algorithm.
So why do people use tables and not one-dimensional arrays? The reason is that we build data-structures in high-level programming languages is because they make sense to us, and help us to come up with systems and save time. Some people, however, say, “OK, we’ve got tables and trees, let’s stop here and go no further.” This is arbitrary, and is basically equivalent to saying: I can get my head around these structures but no further, so let’s stop here.
To illustrate, I’d like to borrow from Paul Graham’s essay Beating the Averages:
Programmers get very attached to their favorite languages, and I don’t want to hurt anyone’s feelings, so to explain this point I’m going to use a hypothetical language called Blub. Blub falls right in the middle of the abstractness continuum. It is not the most powerful language, but it is more powerful than Cobol or machine language.
And in fact, our hypothetical Blub programmer wouldn’t use either of them. Of course he wouldn’t program in machine language. That’s what compilers are for. And as for Cobol, he doesn’t know how anyone can get anything done with it. It doesn’t even have x (Blub feature of your choice).
As long as our hypothetical Blub programmer is looking down the power continuum, he knows he’s looking down. Languages less powerful than Blub are obviously less powerful, because they’re missing some feature he’s used to. But when our hypothetical Blub programmer looks in the other direction, up the power continuum, he doesn’t realize he’s looking up. What he sees are merely weird languages. He probably considers them about equivalent in power to Blub, but with all this other hairy stuff thrown in as well. Blub is good enough for him, because he thinks in Blub.
This is to say that if you’re a table-head, everything simpler than tables (e.g. linear) isn’t powerful enough because you need x feature; everything more powerful than tables (e.g. Hyperstructure Syntax) is just weird because you can’t imagine how you’d use these features. It is of course quite dangerous to think in these terms: you can’t just assume that your framework is the more powerful and call everyone else blub-heads; you need to prove that your system can actually do more.
Paul Graham, in his essay, claims that in any situation one should use the most powerful language available: I actually designed the Hyperstructure Syntax for this purpose, to be the most powerful means of expressing information structure. But I think that the reader deserves a little more reasoning as to how it’s actually helpful.
I think an important question to ask is: “What system would we create to make it most natural to create things that matter to and are important to humans.” Beyond what such a system can do, to what would it lend itself?
What we build in on the build-focused level affects what it is natural to build on the use level: certain assumptions and paradigms on the build level (most notably the hierarchical UNIX filesystem and the relational database) act as blinkers on what we can achieve on the use level. See also HTML, which combines content, structure and formatting into a mess that precludes re-use and remixing, and damns us to a world of one-way links.
With a build level that is naturally flexible and expressive, it will be natural to build a use layer that appeals to real human needs.
Rare Features Matter, too
Another important response to the criticism leveled by my conversational partner is that the frequency of use of particular structures doesn’t necessarily correspond to their actual value. Seeing that most of modern computing is built on the table and the hierarchy/tree, one might assume that these are the most valuable structures (we have few tools that let us break out of tables so it’s not really a fair test).
The counterpoint here is what I call the “Break Glass in Case of X” feature, by which I mean feature that is used rarely but that is extremely important, much like a fire alarm or emergency brake, that are really used by utterly vital and that need to work perfectly when activated.
The software features of this type may or may not be emergency features, some are just very important and used rarely. One emergency example is the wonderful Panic button displayed on the main screen of the ZynAddSubFX software synthesizer found on many Linux distributions, which cuts all sound sources and effects—perfect for if one has created a deafening cacophony.
The non-emergency “table of contents” creators present in many word processors are similar in usage: one uses them rarely (some people never use them) but they are extremely useful when you do use them, saving both time and frustration.
Of course, many Break Glass In Case of X features don’t exist. Here are just two examples of my own:
- Version history tree: Currently, all editors (word processors, spreadsheets, etc.) allow you to hit undo and redo, but if you make an edit after hitting undo a number of times, the previous branch of edits is destroyed. With a tree, you’d be able to maintain the last furthest edit as a preserved branch and make a new branch when you edit. This is a nice example because it shows the destruction that arises when you try to compress the true nature of a particular data structure (an edit tree) into a more simple structure (linear).
- Copy and paste stream: Copying and pasting multiple items from one place to another can be extremely tedious; imagine if you could copy and paste a number of items into your clipboard like a magazine, then hit a button to paste them one by one into where you need them.
Put it this way: the commonality of software features is most likely power-law distributed: this is to say that there are a few functions that will be used extremely frequently, such as, in a word processor, typing characters via the keyboard. Then, as you dream up more obscure and complex functions, their usage is rare and provision for them less extensive, till we get features that aren’t even codified at all. Or sometimes there are combinations of features that are so obvious and connected that it’s a wonder it took us so long to build them, such as the “e” shortcut in the amazing Superhuman mail client, which archives the current message and opens the next.
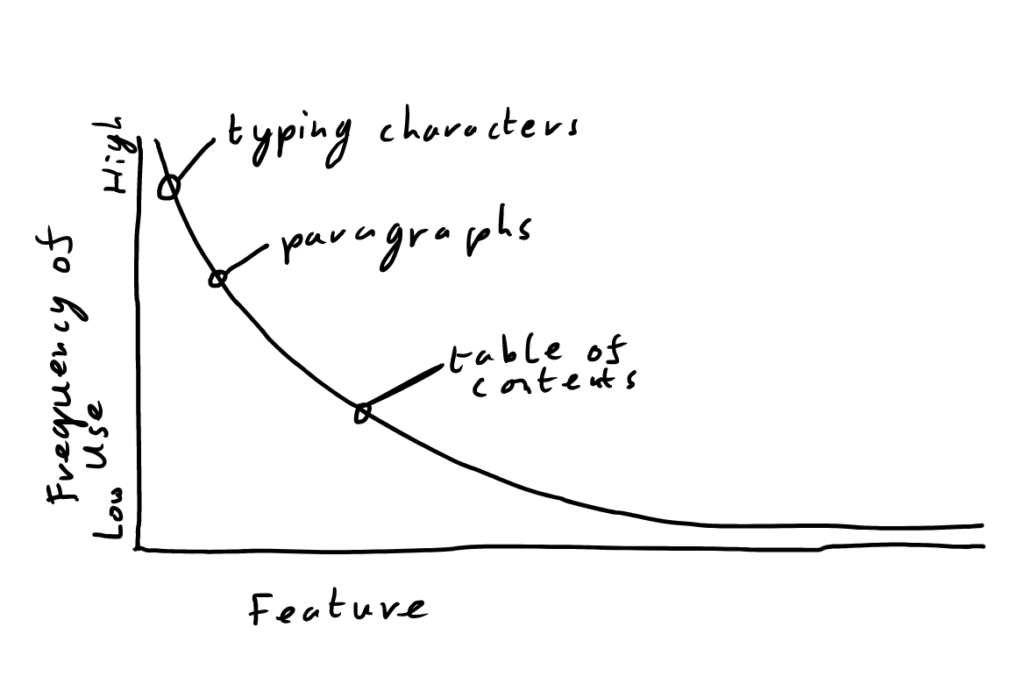
What I think we miss somewhat is that fact that there are certain feature that you might use only once per day or even per year that absolutely need to be fast, simple and easy, if not to save time but simply to save mental effort and frustration. It may take only a few minutes of copying and pasting to perform a certain task that could otherwise have been a feature, but this copying and pasting work feels bad because, to the extent that it is regular and consistent, it could be automated.
Indeed, the features that need to exist but exist only in an obtuse way are perhaps those most that demand our attention. The best example is Google: Google’s index is partly based on links; it weighs the quality of a webpage on (among other things) the number of links that point to it. Google’s index is build by tediously viewing and recording the contents (and links within) each page on the Web.
However, none of this would have been necessary if we had a proper hypertext system, one wherein links are visible from all the pages to which they pertain. On the Web, the link is stored in the webpage, therefore is visible only when on the page—if I’m on the page to which a given link points, I don’t necessarily know there’s a link pointing to it. How could I? It’s for this reason that we have Google, and that it’s machines have to go through the tedium of seeing that points to what—if we had a proper hypertext system, we would just know this information already.
But this feature, knowing the sum total of links and by extension how a given page fits in, was so important to how we understand information that we had to build it, even in a perverse way (Google).
A Note on Ideisomorphism
It’s been some time since I last spoke about the idea of ideisomorphism, but now I think it is a good time to do so again. To recap, something is ideisomorphic or has the quality of ideisiomorphism when it is flexible enough to express human imagination and if its nature lends itself to this type of expression. I think that our tools of computing, and particularly our tools of information management should be ideisomorphic.
Current technology makes it practically impossible to achieve ideisomorphism. The build layer precludes it: it is theoretically possible to do anything computable in any environment, but some environments make it particularly difficult to do what you need to to. As such, I recommend that we make the middle layer fully capable of isomorphism, thus making it easy and natural to build ideisomorphic tools.
Concurrently, I have another priority: extending the capabilities of the build layer to include some graphical capabilities whose main purpose is to make it simple and easy on an entry level for users to configure and work with the middle layer. This should not be patronizing or simplistic, nor should it conceal the meaning of things, rather it should make the function of things and how they work clear and visible, and should follow a consistent structure and set of rules to make it appeal to peoples intuition.
This vision is for HSM: HSM provides users with the syntax for expressing structure and a UI that can display and allows users to create all manner of structures. It is therefore the bridge between the human and the computer—and therefore today between humans and other people—it is a channel that has the level of fidelity actually required to set down are ideas and to express information as it really is.
Conclusion: the Medium and the Message
To conclude, I’d like to explore the three layers of computing for a moment again, and express a vision for the future. Our three layers, remember, are the hardware layer (which always deals in linear data) the use layer (where find the user interface) and finally the build layer (where we find the guts, in which those who create programs operate, and where you need to go to have full control).
To quote Marshall McLuhan:
…the “content” of any medium is always another medium. The content of writing is speech, just as the written word is the content of print, and print is the content of the telegraph.
…the medium is the message. This is merely to say that the personal and social consequences of any medium—that is, of any extension of ourselves—result from the new scale that is introduced into our affairs by each extension of ourselves, or by any new technology.
Marshall McLuhan
This, I hope, resembles the system which we built earlier: the machine layer is the medium for the message of the building layer, the building layer is the medium for the message of the use layer. Meanwhile, the medium is the message we receive: media scale the space and possibility of our action. The message of the build layer is, ultimately, bound by the nature of the machine layer; the message of the use layer is bounded by the build layer.
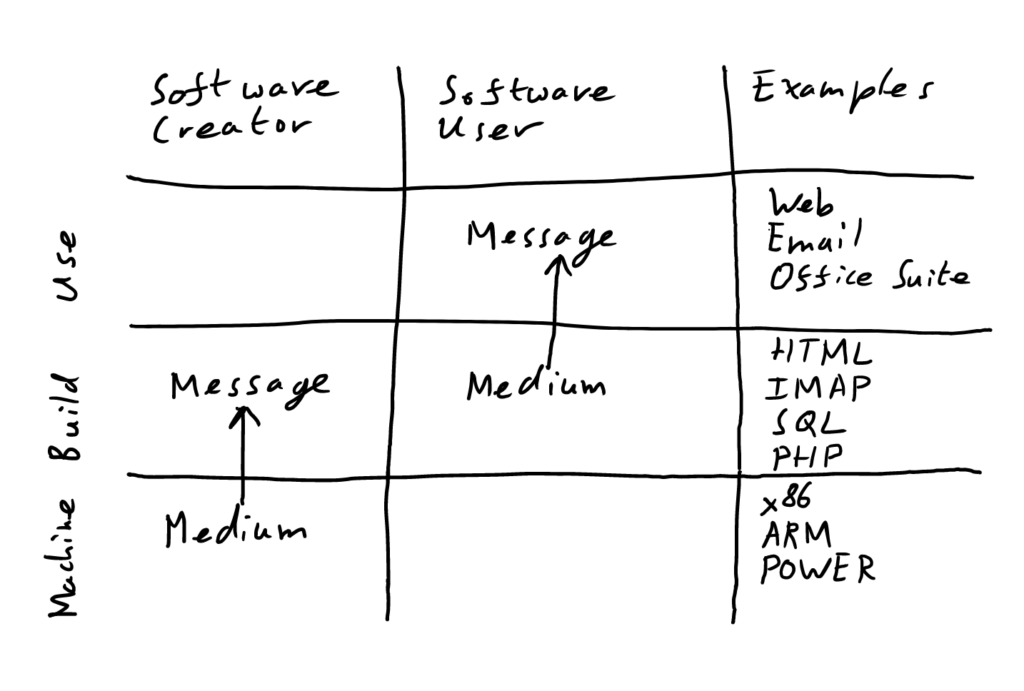
Meanwhile, with software and particularly the use layer, we’re in engaging in a new media game: in previous media-message chains, the each link is visible: the library (medium) contains a book (message); the book (medium) contains print (message); the print (medium) contains a story (message); at every stage we can see the medium that contains a particular message and we can see all media at once.
But in computers, the use-layer hides the build layer, often totally. Where I can still see the paper between the words and letters and am reminded that I’m reading newspaper, modern computing does everything it can to hide the vital build layer. As a counterpoint, many Linux distributions, my preferred system, still boot in text mode, reminding the user that their operating environment is build on top of a system of libraries, programming languages; it is not a pure phantasm:
Hiding the medium doesn’t improve or purify the message, it merely lowers the chance that the user will realize that their software is not perfect (as if descended from heaven) but flawed, contingent and mutable.
This layer-hiding has the potential also to fool users as to whether (when they’re unable to do something) it’s impossible because it really can’t be done or whether it was made impossible (intentionally or accidentally) by programming. The way most build tools operate allows you to attempt much more, and when you do something that can’t be completed, they should tell you why.

User interfaces, however, rarely make it possible to get into this situation: they’re pretended pseudo-physical worlds that make what they preclude impossible to ask for. For example, dragging and dropping a file from one folder to the other leads us to think in terms of a metaphor of an object that can be in one place at a time, though it is technically possible for a file to be in more than one place.
A file upload dialogue that only allows file to be uploaded at a time will often not permit the user to select more than one file—it pretends that it is not possible to upload more than one file, as if you have to let go of an object to pick up another. Instead of this falsehood, software should be more explicit: it’s theoretically possible to upload more than one file but in this instance you can’t because X.
The user interface is a figment of our imagination; the real operations happen in the build layer, but modern UIs attempt to make us forget that the build layer exists. This must be resisted, or we will forever be fooled by interfaces into thinking that restrictions and limitations are necessary and natural regardless of the extent to which they really are.